[Redis] Cluster (1)이론-1
Cluster 이론 1번째 :
Redis Cluster를 설계하기 위해 Redis Cluster에 대한 특징을 자세히 알아보겠다.
1. 데이터 분산 저장 방식
1.1. Sharding
-
각 노드마다 다른 데이터 저장
-
읽기 작업의 부하를 줄이는 방식
1.2. Replication
- 같은 데이터를 복사해 여러 노드에 분산 저장
1) 마스터-슬레이브
-
여러 노드에 데이터를 복제하여 사용
- 쓰기는 마스터에서만 처리, 읽기는 보통 마스터나 슬레이브에서 처리
- 읽기가 많이 발생하는 작업에서 성능 효과
- 마스터의 변경사항이 슬레이브에게 업데이트되기 전에 다른 클라이언트가 읽기 작업을 실행하는 경우 데이터 일관성 침해
2) 피어-투-피어
-
별도로 마스터를 두지 않고 모든 노드가 마스터이자 슬레이브
- 모든 복제본의 가중치는 동일
- 모든 노드가 서로 읽기/쓰기 작업 동기화
- 서로 다른 클라이언트에서 서로 다른 노드의 같은 데이터에 읽기/쓰기 작업 진행하는 경우 데이터 일관성 침해
2. Redis Cluster 란?
- Redis Cluster는 Sharded-Replication
- 확장성 확보를 위한
Sharding: 데이터를 2개 이상의 서버에 동시에 분산 저장- 데이터를 분산 저장하는 목적은 초당 10만 건 이상의 데이터를 빠르게 저장하는 것이다.
- 하나의 서버에 장애 발생 시 분산 처리가 불가능하기 때문에 Master 3대 권장한다.
- 안정성 확보를 위한
Replication: 분산 서버마다 복제 서버를 두어 데이터 유실 방지
- 확장성 확보를 위한
3. Redis Cluster 특징
-
Master와 Replica로 구성
-
Master를 여러 개 둘 수 있음
- 분산 저장(Sharding)이 가능하다.
- 데이터를 여러 서버에서 처리함으로써 특정 서버에 트래픽이 집중되는 것을 분산시킨다.
- Scale-out이 가능하기 때문에 서버를 늘릴수록 저장할 수 있는 공간이 무한대로 커진다.
- 데이터 저장 시 여러 개의 Master 노드 중 한 Master 노드에만 데이터 저장된다.
- 최소 3개의 Master 노드가 있어야 Cluster 구성이 가능하다.
- Sentinel의 경우, Sentinel이 노드들을 감시했지만, Cluster 에서는 모든 노드가 Cluster bus 를 통하여 서로 감시한다.
-
Master 하나에 하나 이상의 Replica 를 둘 수 있음
- Replica는 읽기(Read-only)만 가능하다.
-
클라이언트가 데이터를 요청한다면?
- 데이터가 여러 노드에 분산 저장이 되어있으면 클라이언트가 데이터를 요청할 때 아래와 같은 과정을 거친다.
- 해당 데이터가 있는 Master 노드에 데이터 요청 → 데이터 받음
- 해당 데이터가 없는 Master 노드에 데이터 요청 → 해당 데이터가 저장된 Master 정보를 알려줌 → 클라이언트는 전달 받은 Master 노드에 다시 요청 → 데이터 받음
- 위 과정을 Redis Cluster가 알아서 해준다.
- 데이터가 여러 노드에 분산 저장이 되어있으면 클라이언트가 데이터를 요청할 때 아래와 같은 과정을 거친다.
-
Replica가 죽는다면?
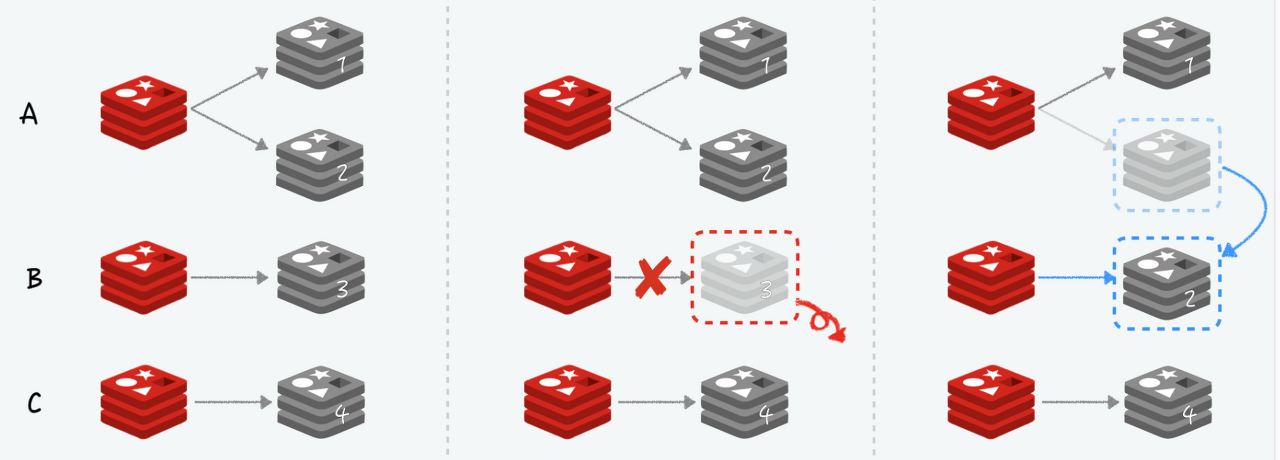
- Replica 노드가 하나도 없는 Master노드 생긴 경우 → 다른 Master에 여유 분이 있을 경우 → 해당 노드를 Replica 노드로 사용
- 위 과정을 Redis Cluster가 알아서 해준다.
-
Master가 죽는다면?
- Replica 노드가 Master로 자동으로 Failover 수행한다.
- 다수의 Master가 죽는다면 무조건 Cluster 중지된다.
4. Redis Cluster 구성
서버가 3대인 경우 Redis Cluster 를 다음과 같이 구성할 수 있다.
4.1. 일반적인 경우
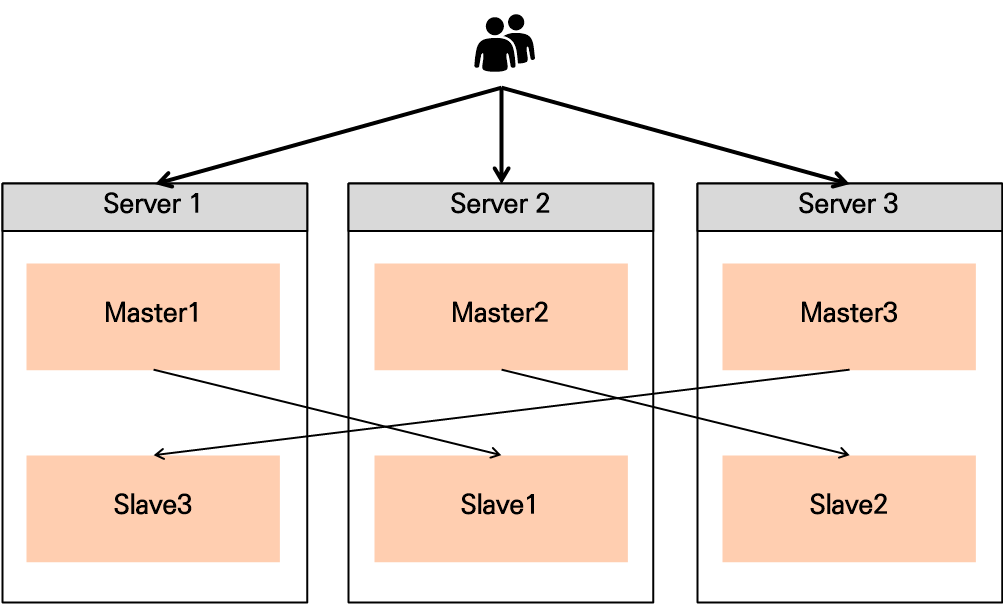
- Master 노드 1개 당 Replica 노드 1개
- 서버 1대가 죽어도 운영이 가능한 형태
4.2. 서버 자원이 충분한 경우
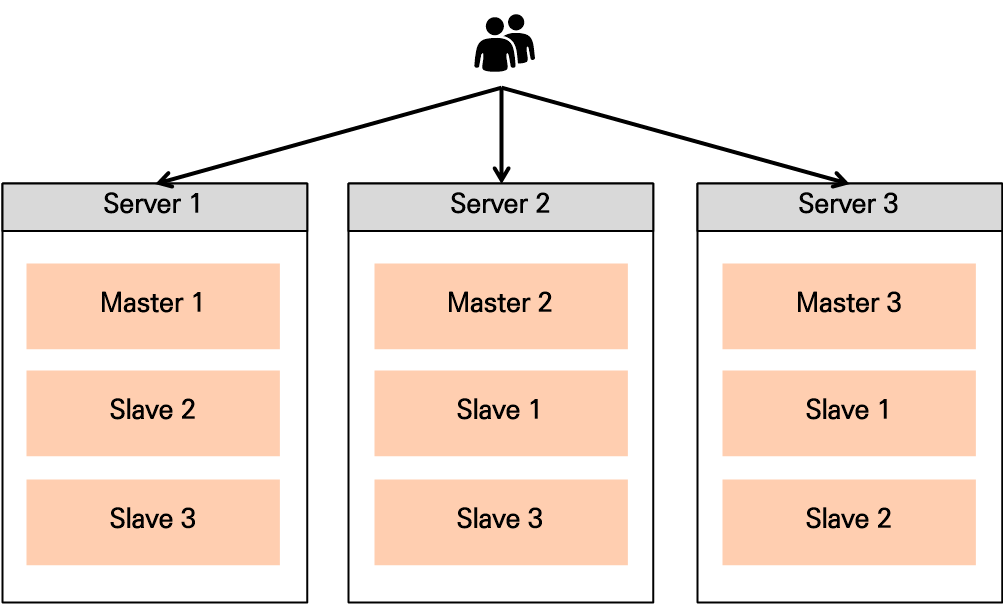
- Master 노드 1개 당 Replica 노드 2개
- 서버가 2대 죽어도 운영이 가능한 형태
5. Redis Cluster 키워드
Redis Cluster의 핵심 키워드에 대해 추가로 알아보겠다.
5.1. Cluster bus
- 노드 간 통신 채널
- 적은 대역폭과 처리 시간으로 노드 간 정보 교환에 적합한 Binary 프로토콜 사용
- 노드들은 장애(Failover) 감지, 구성 업데이트, Failover 권한 부여 등을 위해 Cluster bus 사용
- 클라이언트는 Cluster bus port 에 접근하지 않음
- 노드 간의 통신을 위해 방화벽에 Node Port, Cluster bus TCP Port 2개 모두 열어야 함
5.2. Hash slot
- Data sharding 시 Hash slot 사용
- 모든 키가 개념적으로 Hash slot의 일부인 다른 형태의 sharding 사용
- Redis Cluster에는 16384 개의 Hash slot이 있음
- 주어진 키에 대한 Hash slot 계산을 위해 key modulog 16384 의 CRC16 사용
- Redis Cluster의 모든 노드는 Hash slot 의 하위 집합을 담당
- 3개의 노드가 있는 경우
- Node A : 0 ~ 5500 까지 Hash slot 포함
- Node B : 5501 ~ 11000 까지 Hash slot 포함
- Node C : 11001 ~ 16383 까지 Hash slot 포함
- 3개의 노드가 있는 경우
- Hash slot 은 Cluster Node 삭제하거나 추가 시 편리하도록 함
- Node D 추가 시 A, B, C 의 Hash slot 의 일부를 D 로 이동
- Node A 제거 시 A 의 Hash slot B, C 로 이동
- Node 가 비어있으면 Cluster 에서 제거 가능
- Hash slot 의 노드 간 이동은 운영 중단할 필요 없음
- multiple key operations 지원
- 단일 명령 실행(전체 트랜잭션, Lua 스크립트 실행)과 관련된 모든 key 들이 동일한 Hash slot 에 속하도록 함
- 사용자는 Hash tags 라는 기능을 통해 여러 키를 동일한 Hash slot 의 일부로 만들 수 있음
- Hash tag 의 핵심
- 키의
{}대괄호 사이에 하위 문자열이 있는 경우 문자열 안에 있는 것만 Hash 됨 - 동일한 Hash tag 를 공유하면 동일한 Hash slot 에 있도록 보장됨
user:{123}:profile,user:{123}:account동일한 Hash slot 에 있음
- 키의
5.3. Consistency guarantees
- Redis Cluster Master-Replica 모델 작동 순서
1) 클라이언트가 Master B 에 쓰기 작업
2) Master B 가 클라이언트에 OK 응답
3) Master B 가 Replica 노드 B1, B2 에 쓰기 전파
- Master B 는 Replica 노드 B1, B2 에 쓰기가 완료되었는지 승인 여부를 기다리지 않고 클라이언트에 OK 응답 보냄
- 만약에 복제 노드에 쓰기가 완료되지 않고 충돌 발생해서 B1 노드가 Master 로 승격되면 데이터 유실 발생
- 따라서 클라이언트에 OK 응답하기 전에 Disk에 데이터베이스 데이터를 Flush 하도록 해야 함
- WAIT 명령어를 통해 동기 복제를 지원한다.
- 단, 동기 복제는 low performance를 야기한다.
- 하지만 그럼에도 쓰기를 수신 받지 못한 복제 노드가 Master 로 승격되는 경우가 발생하는 등 강력한 일관성을 구현하지는 못한다.
