[Redis] Cluster (2)설계
Cluster 설계 :
Redis Cluster를 구축하기 위해 설계를 해보겠다.
1. Cluster 구성
- Redis를 위해 가용 가능한 서버는 3대
- 각 서버에서 할당 가능한 메모리가 최대 2GB이기 때문에 Master:Replica는 1:1 비율로 총 Master 노드 3개, Replica 노드 3개로 구성하겠다.
- Port 번호는 각 Master와 연결된 Replica를 구분하기 위해 아래 그림과 같이 지정하겠다.
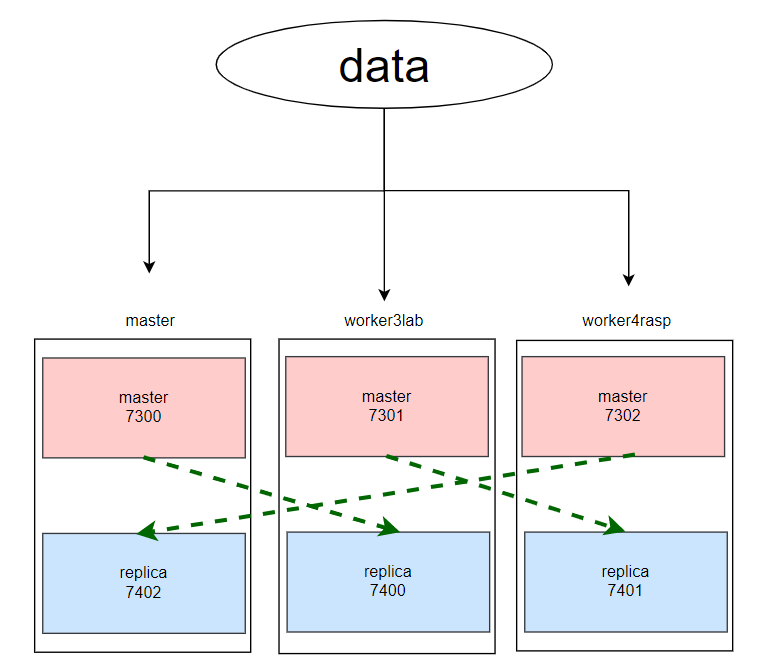
2. 우선 순위
Redis Cluster 설계 시 고려해야 하는 우선 순위는 다음과 같다.
-
데이터 유실 최소화 및 정확한 데이터 저장
-
로그 데이터는 핵심 자산이다.
-
Redis 저장 방식 특성 상 Redis 서버가 다운되면 모든 데이터가 Flush 된다.
-
persistence 기능을 통해 데이터 유실 최소화를 한다.
-
-
가용 메모리 2GB 이내 작동
- Redis 가 작동하는 각 인스턴스에 다른 프로세스들도 존재한다.
- 메모리 충돌을 방지하기 위해 할당 가능 메모리는 최대 2GB로 제한한다.
- 성능 이슈가 있는 swap 메모리는 최대한 사용하지 않는 방향으로 진행한다.
- maxmemory 설정을 통해 메모리를 제한한다.
3. 설계
위에서 언급한 2가지 우선 순위를 고려하여 다음과 같이 Redis Cluster 를 설정한다.
3.1. 데이터 백업 방식
- RDB 대신 AOF 사용
- RDB 는 AOF 에 비해서 큰 데이터를 빠르게 Restart 할 수 있다.
- 하지만 이번 프로젝트에서 Redis에 저장할 데이터는 당일 로그 집계 데이터이고, 당일이 지나면 flush할 예정이기 때문에 큰 데이터를 로드할 일이 없다.
- 또한, RDB 는 자식 프로세스를 이용하는
fork()가 필요한데 데이터가 너무 크면 시스템 부하가 발생한다. - AOF 는 상대적으로
fork()를 자주 하지 않으며, rewrite 를 어떻게 하느냐에 따라 RDB 보다 훨씬 좋은 성능을 발휘한다. - AOF 는 appendonly 이기 때문에 검색이 없고 장애 시에도 문제 없으며 손쉽게 복구 가능하다.
- 만일 실수로
FLUSHALL명령어를 입력해서 flush 가 발생하더라도 즉시 서버 shutdown 후 appendonly.aof 파일에서FLUSHALL명령어 제거 후 redis 다시 시작하면 데이터 손실 없이 DB 살릴 수 있음
- 만일 실수로
3.2. maxmemory 제한
1) maxmemory 선정 시 고려 사항
- 서버 1개 당 가용 메모리는 2GB
- 각 서버들에는 Redis뿐만이 아니라 Hadoop, Spark, Elasticsearch 등 다양한 플랫폼이 존재한다.
- 따라서 프로세스 충돌이 일어나지 않도록 2GB 로 제한한다.
- 하지만 단순히 maxmemory를 2GB 로 설정하면 안 된다.
- 설정파일의 maxmemory는
fork()와 같은 프로세스 발생 시 사용하는 메모리는 포함되지 않는다. - 다음과 같은 식을 만족해야 한다.
- 2GB >= Master(buffer + cache + Redis 저장 데이터) + Replica(buffer + cache + Redis 저장 데이터)
- Master maxmemory = Replica maxmemory
- Master과 Replica 설정 파일에 들어가는 maxmemory는 저장된 데이터의 최대 용량이기 때문에 동일하게 해주는 것이 좋다.
- 일반적으로는 가용 메모리의 60-70%를 maxmemory 로 설정
- 보통은 maxmemory 를 가용 메모리의 60-70%로 지정한다.
- 서비스가 응답 시간에 민감하다면 swap 메모리를 쓰지 않도록 가용 메모리의 50% 이하로 설정하는 게 안전하다.
- RDB save 시 2배 메모리 사용
- RDB를 비활성화해도 Replication을 사용 시, RDB save 프로세스는 사용된다.
- 위에서 RDB를 사용하지 않는다고 했지만 Replication을 사용하기 때문에 RDB save 프로세스가 사용된다는 것을 고려했다.
2) Case 1 : 최악의 경우 고려
- Master 가용 메모리 = Replica 가용 메모리
- buffer 및 overhead 가 가용 메모리의 30% 사용
- 최악의 경우, RDB save 시 저장된 데이터 용량의 2배 메모리 사용
# Master Node
- maxmemory 350MB : 2GB > 1GB > 700MB(300MB) > 350MB(650MB) = 1.05GB
# Replica Node
- maxmemory 350MB : 2GB > 1GB > 700MB(300MB) > 350MB(650MB) = 1.05GB
3) Case 2 : RDB save하는 Master 노드에 더 많은 메모리 할당
- Master 가용 메모리 > Replica 가용 메모리
- Replica에 데이터를 복제하기 위해 RDB save 하는 Master에게 메모리 많이 할당한다.
- 단, Master 노드가 죽었을 경우 Replica가 Master로 승격되는데 해당 Replica 노드가 RDB save하게 되는 경우의 최악의 경우는 미고려한다.
- Master가 죽지 않는다는 가정 하에 최악의 경우 / 최악이 아닌 경우 고려
- 여기서 최악의 경우란, RDB save 발생 시 저장된 데이터 2배의 메모리를 차지하는 경우를 의미한다.
# Master Node
- maxmemory 450MB : 2GB > 1.2GB > 840MB(360MB) > 450MB(750MB) = 1.35GB
- maxmemory 420MB : 2GB > 1.2GB > 840MB(360MB) > 420MB(780MB) = 1.26GB
# Replica Node
- maxmemory 450MB : 2GB > 0.8GB > 560MB(240MB) > 450MB(350MB) = 1.35GB
- maxmemory 420MB : 2GB > 0.8GB > 560MB(240MB) > 420MB(380MB) = 1.26GB
4) Case 3 : RDB save할 때의 사용 메모리도 남긴 메모리에서 해결 가능
- Master 가용 메모리 = Replica 가용 메모리
- maxmemory(저장 데이터)와 프로세스용(RDB + buffer + cache) 반반
- 가용 메모리의 60%를 maxmemory + RDB 용으로 미할당
- 가용 메모리의 70%를 maxmemory + RDB 용으로 100 추가 할당
# Master Node
- maxmemory 600MB : 2GB > 1GB > 600MB(400MB) = 1.8GB
- maxmemory 500MB : 2GB > 1GB > 600MB(400MB) > 500MB(500MB) = 1.5GB
- maxmemory 600MB : 2GB > 1GB > 700MB(300MB) > 600MB(400MB) = 1.8GB
# Replica Node
- maxmemory 600MB : 2GB > 1GB > 600MB(400MB) = 1.8GB
- maxmemory 500MB : 2GB > 1GB > 600MB(400MB) > 500MB(500MB) = 1.5GB
- maxmemory 600MB : 2GB > 1GB > 700MB(300MB) > 600MB(400MB) = 1.8GB
5) Case 4 : Case2 + Case3
- Master 가용 메모리 > Replica 가용 메모리
- maxmemory(저장 데이터)와 프로세스용(RDB + buffer + cache) 반반
- 가용 메모리의 60%를 maxmemory + RDB 용으로 미할당
- 가용 메모리의 70%를 maxmemory + RDB 용으로 100 추가 할당
# Master Node
- maxmemory 840MB : 2GB > 1.2GB > 840MB(360MB) = 2.52GB
- maxmemory 600MB : 2GB > 1.2GB > 840MB(360MB) > 600MB(600MB) = 1.8GB
- maxmemory 620MB : 2GB > 1.2GB > 720MB(480MB) > 620MB(580MB) = 1.86GB
# Replica Node
- maxmemory 480MB : 2GB > 0.8GB > 480MB(320MB) = 1.44GB
- maxmemory 400MB : 2GB > 0.8GB > 480MB(320MB) > 400MB(400MB) = 1.2GB
- maxmemory 660MB : 2GB > 0.8GB > 560MB(240MB) > 660MB(340MB) = 1.98GB
6) 최종 결정
- 팀원들과 회의를 통해 Case1 으로 결정
- Redis 에 저장하는 데이터가 당일 발생한 로그 집계 데이터와, 에코포인트 적립 캐시 데이터임을 고려했을 때 1GB를 넘지 않을 것으로 예상되었다.
- 따라서 최악의 경우까지 고려한 첫 번째 옵션으로 진행하였다.
- Redis 가 설치된 노드에 다른 프로세스도 있기 때문에 Redis 저장 데이터에 maxmemory를 적게 할당해도 자원 낭비가 아니다.
4. 설정 파일
위 설계안을 바탕으로 설정 파일을 다음과 같이 수정한다. 여기서는 Server1 에 해당하는 Master과 Replica 파일을 보여주겠다. 나머지 노드들은 포트 번호만 바꿔주면 된다.
4.1. Master Configuration
-
Server 1 : Port 7300
include /home/ubuntu/redis-cluster/redis.conf # Basic protected-mode no daemonize yes bind 0.0.0.0 port 7300 timeout 2 pidfile /home/ubuntu/redis-cluster/7300/redis_7300.pid dir /home/ubuntu/redis-cluster/7300 databases 16 # AOF persistence appendonly yes appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 30mb # Limit maxclients 10 maxmemory 350mb maxmemory-policy noeviction # Logging/Monitoring loglevel verbose logfile /home/ubuntu/redis-stable/redis-cluster/7300/redis-7300.log latency-monitor-threshold 25 # Cluster cluster-enabled yes cluster-config-file node-7300.conf cluster-node-timeout 5000 cluster-slave-validity-factor 10 cluster-allow-reads-when-down yes cluster-announce-ip [현재 서버의 공인ip] # LazyFree lazyfree-lazy-eviction yes lazyfree-lazy-expire yes lazyfree-lazy-server-del yes replica-lazy-flush yes lazyfree-lazy-user-del yes
4.2. Replica Configuration
-
Server1 : Replica 7402
include /home/ubuntu/redis-cluster/redis.conf # Basic protected-mode no daemonize yes bind 0.0.0.0 port 7402 timeout 2 pidfile /home/ubuntu/redis-cluster/7402/redis_7402.pid dir /home/ubuntu/redis-cluster/7402 databases 16 # AOF persistence appendonly yes appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 30mb # Replication slave-serve-stale-data no repl-ping-slave-period 10 repl-timeout 60 # Limit maxclients 10 maxmemory 350mb maxmemory-policy noeviction # Logging/Monitoring loglevel verbose logfile /home/ubuntu/redis-cluster/7402/redis-7402.log latency-monitor-threshold 25 # Cluster cluster-enabled yes cluster-config-file node-7402.conf cluster-node-timeout 5000 cluster-slave-validity-factor 10 cluster-allow-reads-when-down yes cluster-announce-ip [현재 서버의 공인ip] # LazyFree lazyfree-lazy-eviction yes lazyfree-lazy-expire yes lazyfree-lazy-server-del yes replica-lazy-flush yes lazyfree-lazy-user-del yes
