[Kafka] Apache Kafka란?
Kafka 이론 1 :
Kafka의 필요성, Kafka의 특징, 사용 케이스
1. Apache Kafka
실시간 데이터 플랫폼, 이벤트 스트리밍 플랫폼, 메시징 시스템이라고 불리우는 Apache Kafka에 대하여 알아보겠다.
1.1. Kafka의 필요성
1) Before Kafka
- Source System과 Target System이 증가하면서 시스템 간 데이터 전송 아키텍처가 복잡해졌다.
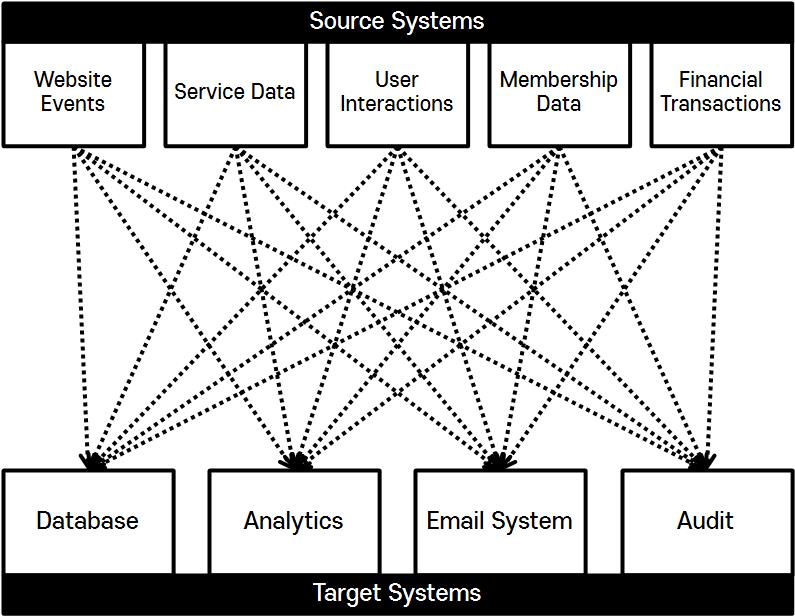
- 5개의 Source System과 4개의 Target System이 있다면, 20개의 Integration을 구현해야 한다.
- Integration에는 다음에 따라 다양한 방식이 존재하기에 20개를 구현하면 복잡성이 증가한다.
- 프로토콜 : 데이터 전송 방식 (TCP, HTTP, REST, FTP, JDBC 등)
- 데이터 형식 : 데이터 파싱 형식 (Binary, CSV, JSON, Avro, Protobuf, Parquet 등)
- 데이터 스키마 진화 : System의 변화로 인한 데이터 형성 방식 변화
- 각 Source System은 모든 Target System들의 데이터 요청과 연결로 인해 로드가 증가한다.
- 또한, 파이프라인 추가 시 이기종 간의 호환성 확인 및 데이터 정합성 등의 번거로운 작업을 수행해야 한다.
- 이와 같이 아키텍처의 복잡성과 종속성 문제를 해결하기 위해 Kafka가 필요하다.
2) After Kafka
- Kafka를 통해 데이터 스트림과 시스템을 분리하고 아키텍처를 단순화한다.
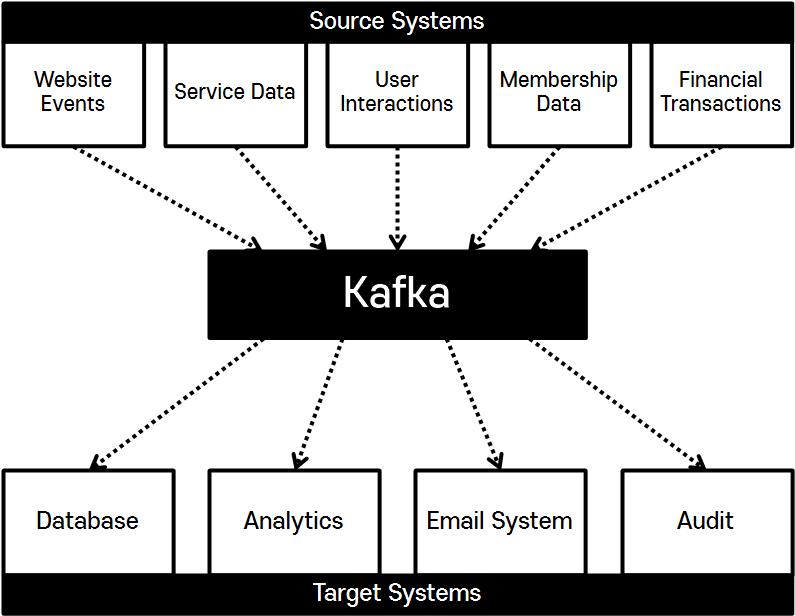
- Source System은 데이터 스트림을 생성해서 Kafka에 전달
- Kafka는 Source System의 데이터 스트림을 보유
- Target System은 필요한 데이터를 Kafka에서 가져옴
1.2. Kafka의 특징
- 높은 처리량과 낮은 지연시간(latency)으로 빠른 응답이 가능하다.
- 응답시간이 한 자리수 밀리초(ms) 단위로 실시간 시스템에 적합
- 수평적 확장 가능하다.
- 클러스터에 수백개의 브로커 추가 가능
- 초당 수백만 개의 메시지 처리 가능
- 고가용성이다.
- replication 지원
- 분산되어 있으며, 내구성(fault tolerant) 높다.
- 시스템 전체를 건드리지 않고도 정비 가능
acks=all: 메시지 내구성 강화 가능- 카프카로 전송되는 모든 메시지는 카프카의 로컬 디스크에 저장
- 컨슈머가 메시지 가져가도 삭제되지 않고 지정한 기간만큼 보관
- 개발 편의성이 있다.
- 프로듀서와 컨슈머가 완벽 분리되어 비동기식 방식으로 동작
- 애플리케이션의 병목 현상 정확히 파악 가능
- 프로듀서와 컨슈머 각각 개발 가능
- 카프카 커넥트 : 코드작성하지 않고도 다양한 프로토콜과 카프카 연동 가능
- 스키마 레지스트리 : 프로듀서와 컨슈머 간 데이터 구조 설명하는 스키마 등록으로 스키마에 정의된 데이터만 주고 받음
- 프로듀서와 컨슈머가 완벽 분리되어 비동기식 방식으로 동작
- 운영 및 관리 편의성이 있다.
- 증설 작업, 무중단 버전 업그레이드, 모니터링 등이 가능
- 그 외 특징은 다음과 같다.
- 이벤트 처리 순서 보장(Partition) : 엔티티 간 유효성 검사 및 동시 수정 필요 없음
- 적어도 한 번 전송 방식 지원 : 누락없는 재전송으로 메시지 손실 리스크 감소(이벤트 중복 발생)
- 백프레셔 핸들링 : 카프카 클라이언트가 pull 방식으로 동작해서 자기 자신의 속도로 처리
- 강력한 파티셔닝 : 논리적으로 토픽 분류, 각 파티션들을 다른 파티션과 관계 없이 처리
- 링크드인, 에어비앤비, 넷플릭스, 우버 등의 많은 대기업이 문제 해결을 위해 택한 시스템
1.3. 사용 케이스
- 데이터 통합
-
메시징 시스템
- 활동 추적 시스템
- 다양한 지역의 측정 지표 수집
- 애플리케이션 로그 수집
- 스트림 프로세싱 (Kafka Streams API)
- 시스템 종속성 분리
- Spark, Flink, Hadoop과 같은 빅데이터 기술과 통합
- 마이크로 서비스의 pub/sub
2. 생각
-
Kafka는 대용량 데이터 플로우를 가능하게 하는 운송 메커니즘이다.
-
데이터 전송 아키텍처의 복잡성과 종속성을 제거하여 데이터 스트림을 별도로 관리 가능하다는 점이 인상 깊었다.
REFERENCES
- [강의] Apache Kafka Series - Learn Apache Kafka for Beginners v3 (Stephane Maarek)
- [서적] 실전 카프카 개발부터 운영까지 (고승범)
