[MongoDB] Spark로 GeoJSON 가공
Geo JSON 가공 :
Spark를 사용하여 위치 데이터를 표준 형태인 GeoJSON로 가공하여 MongoDB에 저장해 보겠다.
1. GeoJSON 과 MongoDB
1.1. GeoJSON이란?
- 위치정보를 갖는 점을 기반으로 체계적으로 지형을 표현하기 위해 설계된 개방형 공개 표준 형식
- JSON을 사용하는 파일 포맷으로 국제 인터넷 표준화 기구 산하 워킹그룹에 의해 작성되고 유지
- XML을 기반으로 한 GPX와 함께 사실상 표준처럼 사용
- 특징
- WGS 84가 권장하는 [경도(longitude), 위도(latitude)] 표기법을 지원한다.
- 경도 : -180 <= 경도 <= 180
- 위도 : -90 <= 위도 <= 90
- 지형 공간 토폴로지를 인코딩하며 일반적으로 파일 크기가 더 작다.
- WGS 84가 권장하는 [경도(longitude), 위도(latitude)] 표기법을 지원한다.
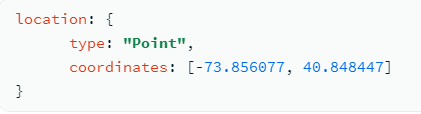
- GeoJSON 형태
<field>: { type: <GeoJSON type> , coordinates: <coordinates> }
1.2. MongoDB의 위치 필터링
- MongoDB는 GeoJSON 개체 타입을 지원
- MongoDB는 GeoJSON 개체에 대한 geo spatial query 에 WGS84 reference 시스템을 사용한다.
Point(점),LineString(선),Polygon(면),MultiPoint,MultiLineString,MultiPolygon,GeometryCollection형태의 데이터를 저장 가능하다.
- MongoDB의 위치 필터링 기능
- MongoDB에 GeoJSON 형식의 위치 데이터를 저장하면 추후 특정 지점과 반경만 입력하면 해당 지점을 기준으로 반경 내에 존재하는 데이터를 모두 가져올 수 있다.
- 이 기능을 사용하면 간단한 쿼리문으로도 쉽게 위치 데이터 추출이 가능하다.
2. Geo JSON 변환
이 포스팅에서는 Point type의 GeoJSON 형식으로 변환해 보겠다.
2.1. 필요한 모듈 가져오기
>>> from pyspark.sql.functions import explode, col, struct, lit, concat, split, array
2.2. 원본 데이터 가져오기
- 원본 데이터는 하둡에 json 확장자로 저장한 공원 데이터를 가져왔다.
>>> df = spark.read.option("multiline", "true").json("hdfs://localhost:9000/user/multi/pjt2/park.json")
>>> df = spark.read.option("multiline", "true").json("pjt2/park.json")
>>> df.show()
+-------------------------+----------------+-----------------------+
| RESULT|list_total_count| row|
+-------------------------+----------------+-----------------------+
|{INFO-000, 정상 처리되...| 132|[{2896887㎡ 임 야 : ...|
+-------------------------+----------------+-----------------------+
2.3. 데이터 가공
1) 필요한 속성만 추출
- 필요 없는 열 RESULT, list_total_count 제거
- row 컬럼 안에 구조체 값 여러 개가 리스트(배열) 형태로 놓아져 있다.
>>> df = df.drop('RESULT', 'list_total_count')
>>> df.show()
+-----------------------+
| row|
+-----------------------+
|[{2896887㎡ 임 야 : ...|
+-----------------------+
- df 에서 row 컬럼의 배열 값들을 행으로 늘어놓기
explode(col('컬럼명'))
>>> df_temp = df.select(explode(col('row')).alias('temp'))
>>> df_temp.show()
+------------------------------+
| temp|
+------------------------------+
| {2896887㎡ 임 야 : 2...|
| {80683㎡, http://p...|
| {9132690m², , 437...|
| {480994㎡, http://...|
| {2284085㎡, http:/...|
| {8948.1㎡, http://...|
|{휴양 및 편익시설 : 평의자 ...|
| {6456㎥, http://pa...|
| {80309㎡ 배수지 시설용량 ...|
| {1980.4㎡ , http...|
| {5197.7㎡ , http:/...|
| {11467㎡ , http://...|
| {229539㎡, http://...|
| {15179.7 ㎡ , http...|
| {16734.60㎥ , http...|
| {61544㎡ 녹지대 : 407...|
| {424106㎡ , http:/...|
| {560552㎡, http://...|
| {26696.8㎥ , http:...|
| {75900㎡, http://p...|
+------------------------------+
- explode한 df_temp의 temp 컬럼 구조 파악
- temp 컬럼의 각 행은 구조체로 구성되어 있고, 구조체 안에 여러 정보가 담겨있다.
- 여기서 필요한 속성은 공원 인덱스, 공원 이름, 공원이 위치한 지역구, 경도, 위도이다.
>>> df_temp.printSchema()
root
|-- temp: struct (nullable = true)
| |-- AREA: string (nullable = true)
| |-- GUIDANCE: string (nullable = true)
| |-- G_LATITUDE: string (nullable = true)
| |-- G_LONGITUDE: string (nullable = true)
| |-- LATITUDE: string (nullable = true)
| |-- LONGITUDE: string (nullable = true)
| |-- MAIN_EQUIP: string (nullable = true)
| |-- MAIN_PLANTS: string (nullable = true)
| |-- OPEN_DT: string (nullable = true)
| |-- P_ADDR: string (nullable = true)
| |-- P_ADMINTEL: string (nullable = true)
| |-- P_IDX: string (nullable = true)
| |-- P_IMG: string (nullable = true)
| |-- P_LIST_CONTENT: string (nullable = true)
| |-- P_NAME: string (nullable = true)
| |-- P_PARK: string (nullable = true)
| |-- P_ZONE: string (nullable = true)
| |-- TEMPLATE_URL: string (nullable = true)
| |-- USE_REFER: string (nullable = true)
| |-- VISIT_ROAD: string (nullable = true)
- 구조체 안에서 필요한 속성만 선택해서 열로 가져오기
- 구조체의 모든 속성 가져오기 :
df.select('temp.*') - 구조체의 특정 속성 가져오기 :
df.select('temp.col1', 'temp.col2', 'temp.col3')
- 구조체의 모든 속성 가져오기 :
>>> park = df_temp.select('temp.P_IDX', 'temp.P_PARK', 'temp.P_ZONE', 'temp.LONGITUDE', 'temp.LATITUDE')
>>> park.show(5)
+-----+------------------------+--------+-----------+----------+
|P_IDX| P_PARK| P_ZONE| LONGITUDE| LATITUDE|
+-----+------------------------+--------+-----------+----------+
| 1| 남산도시자연공원| 중구|126.9903773|37.5501402|
| 2| 길동생태공원| 강동구|127.1547791|37.5403935|
| 3| 서울대공원| 과천시|127.0198465|37.4264494|
| 4| 서울숲| 성동구|127.0417982|37.5430717|
| 5| 월드컵공원| 마포구| 126.878907| 37.571805|
+-----+------------------------+--------+-----------+----------+
2) type 속성 생성
- GeoJSON 형태로 변환하기 위해서는 데이터가 어떤 종류(Point, LingString, Polygon)인지 명시해주는 type 열필수
>>> park = park.select("*", lit("Point").alias("type"))
>>> park.show(5)
+-----+------------------------+--------+-----------+----------+-----+
|P_IDX| P_PARK| P_ZONE| LONGITUDE| LATITUDE| type|
+-----+------------------------+--------+-----------+----------+-----+
| 1| 남산도시자연공원| 중구|126.9903773|37.5501402|Point|
| 2| 길동생태공원| 강동구|127.1547791|37.5403935|Point|
| 3| 서울대공원| 과천시|127.0198465|37.4264494|Point|
| 4| 서울숲| 성동구|127.0417982|37.5430717|Point|
| 5| 월드컵공원| 마포구| 126.878907| 37.571805|Point|
+-----+------------------------+--------+-----------+----------+-----+
3) 위도, 경도 합치기
- LONGITUDE와 LATITUDE 속성을 하나의 배열에 묶어서 coordinates 속성에 넣기
- 두 속성을 묶는 방법 2가지
concat()과split()을 사용하는 방법array()를 사용하는 방법
- 속성을 묶으면서 속성 이름도 다음과 같이 변경
- park_id, park_nm, park_gu, location(coordinates, type)
- 방법1 :
concat()과split()- 먼저
concat()과split()으로 배열을 만들었는데 이런 경우 문자열로 묶어야 한다. - 하지만 GeoJSON의 위치 coordinates 값들은 데이터 타입이 숫자여야 하기 때문에 번거롭다.
- 먼저
>>> park = park.select(col('P_IDX').alias('park_id'),
col('P_PARK').alias('park_nm'),
col('P_ZONE').alias('park_gu'),
concat(col('LONGITUDE'), lit(' '),
col('LATITUDE')).alias('coor_temp'), col('type'))
>>> park.show(5)
+-------+------------------------+--------+--------------------+-----+
|park_id| park_nm| park_gu| coor_temp| type|
+-------+------------------------+--------+--------------------+-----+
| 1| 남산도시자연공원| 중구|126.9903773 37.55...|Point|
| 2| 길동생태공원| 강동구|127.1547791 37.54...|Point|
| 3| 서울대공원| 과천시|127.0198465 37.42...|Point|
| 4| 서울숲| 성동구|127.0417982 37.54...|Point|
| 5| 월드컵공원| 마포구|126.878907 37.571805|Point|
+-------+------------------------+--------+--------------------+-----+
>>> park = park.select('*', split(col('coor_temp'),
' ').alias('coordinates')).drop('coor_temp')
>>> park.show(5)
+-------+------------------------+--------+-----+--------------------+
|park_id| park_nm| park_gu| type| coordinates|
+-------+------------------------+--------+-----+--------------------+
| 1| 남산도시자연공원| 중구|Point|[126.9903773, 37....|
| 2| 길동생태공원| 강동구|Point|[127.1547791, 37....|
| 3| 서울대공원| 과천시|Point|[127.0198465, 37....|
| 4| 서울숲| 성동구|Point|[127.0417982, 37....|
| 5| 월드컵공원| 마포구|Point|[126.878907, 37.5...|
+-------+------------------------+--------+-----+--------------------+
- 위도, 경도 합치기 (2)
- 따라서
array()함수가 더 효율적이다.array([col1, col2]).alias('coordinates')
- 배열로 생성하기 전에 LONGTITUDE와 LATITUDE의 데이터 타입이 string이니 float으로 변환해준다.
- 만일
col('컬럼명').cast('float')에서 에러가 발생한다면 null값 때문에 숫자로 변경되지 않는 것일 수도 있으니df.na.replace("", "0")를 사용한다.
- 따라서
park = park.select(col('P_IDX').alias('park_id'),
col('P_PARK').alias('park_nm'),
col('P_ZONE').alias('park_gu'),
array([col('LONGITUDE').cast('float'),
col('LATITUDE').cast('float')]).alias('coordinates'),
col('type'))
4) location 속성 생성
- type과 coordinates 속성을 location 속성 안에 구조체로 넣기
struct(col1, col2).alias('location')- 기존에 있던 type과 coordinates 속성은 제거한다.
>>> park = park.select('*', struct(col('type'),
col('coordinates')).alias('location'))\
.drop('type', 'coordinates')
>>> park.show(5)
+-------+----------------+-------+--------------------+
|park_id| park_nm|park_gu| location|
+-------+----------------+-------+--------------------+
| 1|남산도시자연공원| 중구|{Point, [126.9903...|
| 2| 길동생태공원| 강동구|{Point, [127.1547...|
| 3| 서울대공원| 과천시|{Point, [127.0198...|
| 4| 서울숲| 성동구|{Point, [127.0417...|
| 5| 월드컵공원| 마포구|{Point, [126.8789...|
+-------+----------------+-------+--------------------+
5) GeoJSON 최종 확인
- location, type, coordinates, 데이터 타입이 올바른지 확인
df.printSchema()
>>> park.printSchema()
root
|-- P_IDX: string (nullable = true)
|-- P_PARK: string (nullable = true)
|-- P_ZONE: string (nullable = true)
|-- location: struct (nullable = false)
| |-- type: string (nullable = false)
| |-- coordinates: array (nullable = true)
| | |-- element: float (nullable = true)
2.4. MongoDB 저장
- pjt2 데이터베이스에 PARK 라는 collection 으로 저장
>>> park.write.format('com.mongodb.spark.sql.DefaultSource') \
.option("uri", "mongodb://localhost:27017/pjt2.PARK") \
.save()
2.5. 최종 코드
- 위 코드를 스크립트로 정리
# PARK.py
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkContext
from pyspark.sql.types import StructType
from pyspark.sql.functions import col, explode, struct, lit, concat, split, array
spark = SparkSession.builder \
.master("yarn") \
.appName("PARK") \
.getOrCreate()
park = spark.read.option("multiline", "true").json("pjt2/park.json") \
.drop('RESULT', 'list_total_count') \
.select(explode(col('row')).alias('temp')) \
.select('temp.P_IDX', 'temp.P_PARK', 'temp.P_ZONE', 'temp.LONGITUDE', 'temp.LATITUDE') \
.select("*", lit("Point").alias("type")) \
.na.replace("", "0") \
.select(col('P_IDX').alias('park_id'),
col('P_PARK').alias('park_nm'),
col('P_ZONE').alias('park_gu'),
array([col('LONGITUDE').cast('float'), col('LATITUDE').cast('float')]).alias('coordinates'),
col('type')) \
.select('*', struct(col('type'), col('coordinates')).alias('location')).drop('type', 'coordinates')
# mongodb pjt2 db에 적재
park.write.mode('overwrite').format('com.mongodb.spark.sql.DefaultSource') \
.option("uri", "mongodb://localhost:27017/pjt2.PARK") \
.save()
- Spark와 MongoDB를 연동해 놓은 경우
- 다음 명령어로 스크립트 실행 가능하다.
# MongoDB 시작
sudo service mongod start
# pyspark 작동 위한 사전 명령어
start-all.sh
# 스크립트 실행
spark-submit PARK.py
- Spark와 MongoDB를 연동해 놓지 않은 경우
- 스크립트에 다음과 같이 config로 연결 설정 필요하다.
# spark에 mongodb를 연결하지 않은 경우
spark = SparkSession.builder \
.master("yarn") \
.appName("BIKE_ROAD") \
.config('spark.mongodb.input.uri', 'mongodb://localhost/test') \
.config('spark.mongodb.output.uri', 'mongodb://localhost/test') \
.config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.12:3.0.1') \
.getOrCreate()
3. 위치 필터링
3.1. 데이터 확인
- PARK collection에 있는 데이터 조회
pjt2> db.PARK.find()
[
{
_id: ObjectId("62efbf55187e6d0719973183"),
park_id: '1',
park_nm: '남산도시자연공원',
park_gu: '중구',
location: { type: 'Point', coordinates: [ '126.9903773', '37.5501402' ] }
},
{
_id: ObjectId("62efbf55187e6d0719973184"),
park_id: '2',
park_nm: '길동생태공원',
park_gu: '강동구',
location: { type: 'Point', coordinates: [ '127.1547791', '37.5403935' ] }
},
{
_id: ObjectId("62efbf55187e6d0719973185"),
park_id: '3',
park_nm: '서울대공원',
park_gu: '과천시',
location: { type: 'Point', coordinates: [ '127.0198465', '37.4264494' ] }
},
...
]
- MongoDB collection에서 20개 이상의 doc를 조회하고 싶은 경우
# mongo 실행
mongosh
# 다음 명령어 입력
DBQuery.shellBatchSize=1000
# 데이터 조회
db.PARK.find()
3.2. 위치 인덱스 생성
- 계산 법 명시
- location 안의 값들을 계산할 건데 2dshpere 방법으로 계산하겠다.
> db.PARK.createIndex({location: '2dsphere'})
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
3.3. 위치 필터링 적용
- 지정 위치 : [127.049767, 37.503466]
1) 지정 위치에서 가까운 위치 순으로 정렬
- 지정 위치 기준으로 가까운 공원부터 데이터 조회
$near,$geometry
> db.PARK.find(
{
location: {
$near: {
$geometry:
{type: 'Point', coordinates: [127.049767, 37.503466]}
}
}
}
)
[
{
_id: ObjectId("62f0b23f44aa4f315259bf08"),
park_id: '64',
park_nm: '봉은공원',
park_gu: '강남구',
location: {
type: 'Point',
coordinates: [ 127.05549621582031, 37.51390075683594 ]
}
},
{
_id: ObjectId("62f0b23f44aa4f315259bef5"),
park_id: '45',
park_nm: '도곡근린공원',
park_gu: '강남구',
location: {
type: 'Point',
coordinates: [ 127.04503631591797, 37.49031448364258 ]
}
},
..
]
2) 지정 위치에서 Nm 이내 위치 조회
- 지정 위치 정보 5000m 거리 안에 있는 공원
$near,$geometry,$maxDistance
> db.PARK.find(
{
location: {
$near: {
$geometry:
{type: 'Point', coordinates: [127.049767, 37.503466]},
$maxDistance: 5000
}
}
}
)
[
{
_id: ObjectId("62f0b23f44aa4f315259bf08"),
park_id: '64',
park_nm: '봉은공원',
park_gu: '강남구',
location: {
type: 'Point',
coordinates: [ 127.05549621582031, 37.51390075683594 ]
}
},
{
_id: ObjectId("62f0b23f44aa4f315259bef5"),
park_id: '45',
park_nm: '도곡근린공원',
park_gu: '강남구',
location: {
type: 'Point',
coordinates: [ 127.04503631591797, 37.49031448364258 ]
}
},
...
]
3) 지정 위치에서 반경 N마일(원) 이내 위치 조회
- 지정 위치에서 3마일 안에 있는 공원 조회
$near,$geoWithin,$centerSphere
> db.PARK.find(
{
location: {
$geoWithin:{
$centerSphere: [[127.02758390096662, 37.498208718241884], 3/3963.2],
}
}
}
)
[
{
_id: ObjectId("62f0b23f44aa4f315259bf3d"),
park_id: '117',
park_nm: '우면산도시자연공원',
park_gu: '서초구',
location: {
type: 'Point',
coordinates: [ 127.0091323852539, 37.47048568725586 ]
}
},
{
_id: ObjectId("62f0b23f44aa4f315259bf32"),
park_id: '106',
park_nm: '문화예술공원',
park_gu: '서초구',
location: {
type: 'Point',
coordinates: [ 127.030517578125, 37.467655181884766 ]
}
},
{
_id: ObjectId("62f0b23f44aa4f315259bedf"),
park_id: '23',
park_nm: '양재시민의숲',
park_gu: '서초구',
location: {
type: 'Point',
coordinates: [ 127.03504180908203, 37.47122573852539 ]
}
},
{
_id: ObjectId("62f0b23f44aa4f315259bee6"),
park_id: '30',
park_nm: '국립현충원',
park_gu: '동작구',
location: {
type: 'Point',
coordinates: [ 126.97368621826172, 37.49986267089844 ]
}
},
{
_id: ObjectId("62f0b23f44aa4f315259bedc"),
park_id: '20',
park_nm: '용산가족공원',
park_gu: '용산구',
location: {
type: 'Point',
coordinates: [ 126.98333740234375, 37.52222442626953 ]
}
},
...
]
[Python으로 처리한 GeoJSON이 궁금하다면?]
