[Spark] Spark Streaming (2)
Spark 이론 3 :
Spark Streaming 순서
1. Spark Streaming 순서
Spark Streaming을 사용할 때 순서를 알아보겠다. 여기에 나온 예시는 scala 언어로 스파크 셸에서 실행하는 코드지만 pyspark와 비슷한 부분이 많기 때문에 이해하는 데는 어려움이 없다.
1.1. StreamingContext 인스턴스 생성
StreamingContext 객체를 초기화하기 위해 SparkContext, Duration 2개의 객체를 사용한다.
- SparkContext 객체 : 기존에 시작한 것을 사용하거나 새로 시작해서 사용 가능
- Duration 객체 : 미니배치 간격을 지정
- 입력 데이터 스트림을 나누고 미니배치 RDD를 생성하는 기준
- Second(초), Millisecond(밀리초), Minute(분) 객체로 주기 지정
1) 기존 SparkContext 객체
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(5))
2) 새로운 SparkContext 객체
- 스파크 설정 객체를 전달하면, 새로운 SparkContext를 시작한다.
- 이 방법은 스파크 독립형 애플리케이션에서만 사용 가능하다.
- 스파크 셸에서 SparkContext 2개 이상을 동일한 JVM에 초기화할 수 없기 때문
val ssc = new SparkConf().setMaster("local[4]").setAppName("App name")
val ssc = new StreamingContext(conf, Second(5))
1.2. 이산 스트림 생성 (DStream 생성)
여기서는 textFileStream 메서드를 활용해 텍스트 데이터를 스트리밍으로 전달하겠다.
1) textFileStream 메서드
- 스트리밍 애플리케이션의 입력 폴더를 지정한다.
SparkContext.textFileStream("디렉터리 경로")
- 지정된 디렉터리를 모니터링해서 새로 생성된 파일만을 개별적으로 읽어온다.
- HDFS, S3, GluterFS, 로컬 등 다양한 유형의 디렉터리를 지정 가능
- StreamingContext를 시작한 시점 이후에 디렉터리에 추가된 파일들만 처리
- 기존 파일은 처리하지 않음
- DStream 클래스의 인스턴스를 반환한다.
- DStream은 스파크 스트리밍 기본 추상화 객체로 RDD 시퀀스를 표현
- DStream은 지연평가되므로 StreamingContext가 시작할 때 RDD가 실제로 유입됨
val filestream = ssc.textFileStream("/home/spark/input")
1.3. 이산 스트림 사용 (코드 작성)
DStream은 이산 스트림을 다른 DStream으로 변환하는 다양한 메서드를 제공한다.
- DStream의 RDD 데이터에 연산(필터링, 매핑, 리듀스) 적용
- DStream 데이터 간 조인, 결합
1) 데이터 파싱
- 각 줄을 다루기 쉬운 객체로 변환한다.
- scala에서는 케이스 클래스로 변환한다.
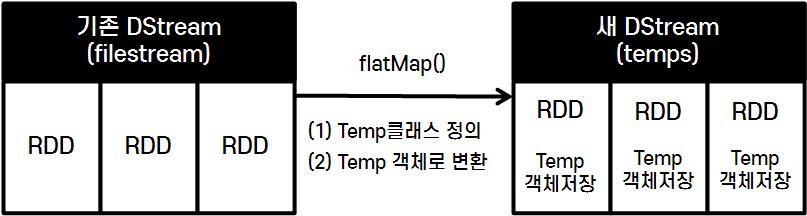
-
객체 생성을 위해 Temp 클래스 정의 (데이터 타입 등 지정)
- Temp 객체 생성 가능
import java.sql.Timestamp case class Temp(time: java.sql.Timestamp, rowId:Long, name:String, amount:Int) -
DStream의 각 줄을 파싱 > Temp 객체로 구성된 새 DStream을 생성
DStream 객체.flatMap()- 모든 RDD를 각 요소 별로 처리하는 변환 연산자
- try~catch를 통해 포맷이 맞지 않는 데이터를 건너뛸 수 있음
import java.text.SimpleDateFormat val temps = filestream.flatMap(line => { val dateFormat= new SimpleDateFomat("yyyy-MM-dd HH:mm:ss") val s = line.split(",") try { List(Temp(new Timestamp(dateFormat.parse(s(0)).getTime()), s(1).toLong, s(2), s(3).toInt)) } catch { case e : Throwable => println("Wrong line format ("+e+"): "+line) List() } })- 반환된 DStream (temps) 의 각 RDD에는 Temp 객체가 저장됨
2) 집계
- 2-요소 튜플로 구성된 DStream은 PairDStreamFunctions 객체로 자동 변환된다.
- PairRDDFunctions와 유사
- combineByKey, reduceByKey, flatMapValues 등의 변환함수 제공
- 집계에 유용하게 활용 가능
3) 결과 저장
- 여기서는 saveAsTextFiles 메서드를 활용해 처리 결과를 저장하겠다.
- saveAsTextFiles
- 인수 : 접두 문자열(필수), 접미 문자열(선택)
- 미니배치 RDD 주기마다 새로운 디렉토리/경로 생성
<접두문자열>-<밀리초단위시각>.<접미문자열>
- RDD의 각 파티션을 위 경로에
part-xxxxx파일로 저장- 하나의 파일로 저장하고 싶은 경우 저장 전 repartition(1) 필수
temps.repartition(1).saveAsTextFiles("/home/spark/output/", "txt")
- 위 코드를 실행해도 StreamingContext를 시작하지 않았기 때문에 변화가 일어나지 않는다.
1.4. StreamingContext 시작과 종료
위에 작성한 코드들은 StreamingContext를 시작하지 전까지 진행되지 않는다.
1) Streaming 처리 시작
- 스파크 셸에서는
ssc.start()명령어를 입력하면 다음과 같이 실행된다.- StreamingContext 시작
- 지금까지 생성한 DStream들 평가
- 리시버 시작 (별도의 리시버에서 구동되기 때문에 스파크 셸에 다른 명령어 입력 가능)
- DStream 연산 수행
- 스파크 애플리케이션에서는
StreamingContext.start메서드 호출로 실행한다.- StreamingContext 와 리시버 시작
- 하지만, 다음 코드를 호출하지 않으면 리시버 스레드가 시작해도 드라이버의 메인 스레드가 종료
- awaitTermination 메서드 : 스트리밍 계산 작업 종료까지 스파크 애플리케이션 대기
- 동일한 SparkContext 객체로 StreamingContext 인스턴스 여러 개 생성 가능하다.
- 하지만, 동일한 JVM에서는 StreamingContext를 한 번에 하나 이상 시작할 수 없다.
2) Streaming 종료
- 스파크 셸에서는
ssc.stop(false)명령어로 StreamingContext를 종료시킬 수 있다.- false : StreamingContext만 종료, SparkContext는 종료 X
- true : default 값으로 모두 종료
3) 출력 결과
- 미니배치 RDD마다 생성된 폴더에 part-xxxxx 파일과 _SUCCESS 파일이 저장되어 있다.
- _SUCCESS : 폴더의 쓰기 작업 성공여부를 저장한 파일
- 각 폴더에 분할 저장되어 있는 파일들을 한 번에 가져와 단일 RDD로 로드할 수 있다.
val allOutput = sc.textFile("/home/spark/output*.txt")
2. 정리
-
SparkContext 객체와 Duration 객체로 StreamingContext를 생성할 수 있다.
-
StreamingContext를 시작하기 전까지는 이산 스트림 처리 코드가 실행되지 않는다.
-
textFileStream 메서드는 텍스트 데이터를 스트리밍으로 전달할 때 사용하며, DStream 인스턴스를 반환한다.
- 스트리밍 시작 시점부터 지정한 디렉토리를 모니터링해서 추가된 파일 데이터를 읽어옴
-
saveAsTextFiles 메서드는 미니배치 RDD 주기별로 폴더를 생성하고 그 안에 파티션별로 파일을 저장한다.
REFERENCES
- [서적] 스파크를 다루는 기술 (페타 제체비치, 마르코 보나치)
