[CS] 기초 : 데이터베이스
데이터베이스 용어 :
DBMS, 키, 타입, 인덱스, 정규화, 트랜잭션, 무결성
1. 개념 구조화
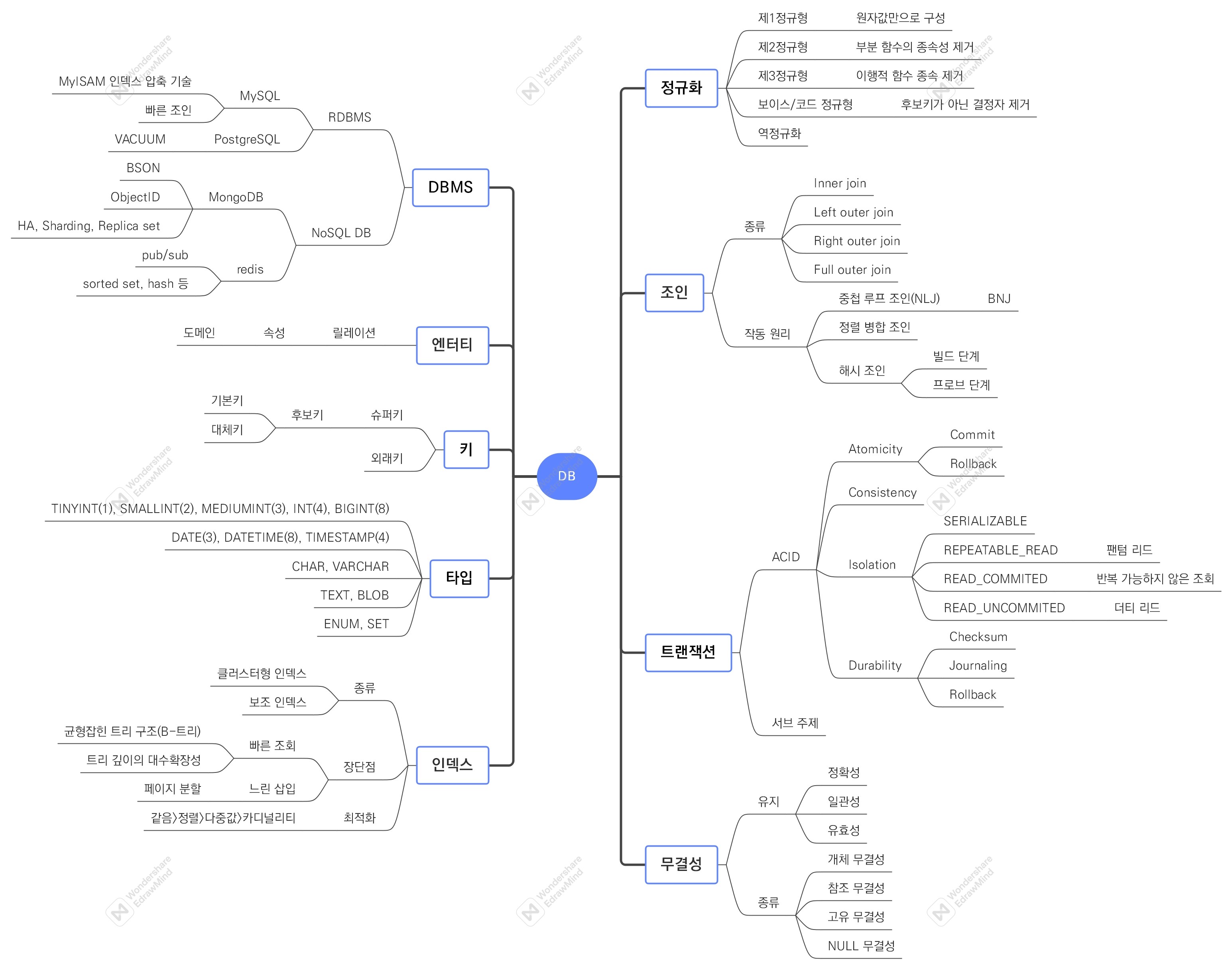
2. 개념 사전
| KOR | ENG | Meaning |
|---|---|---|
| 데이터베이스 | Database | - 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되는 데이터 모음 - 실시간 접근과 동시 공유 가능 |
| DBMS | Database Management System | - 데이터베이스를 제어, 관리하는 통합 시스템 |
| 엔터티 | Entity | - 사람, 장소, 물건, 사건 등 여러 개의 속성을 지닌 명사 - 약한 엔터티와 강한 엔터티 |
| 릴레이션 | Relation | - 데이터베이스에서 정보를 구분하여 저장하는 기본 단위 - 엔터티 -> 릴레이션 (컬렉션/테이블) -> 도큐먼트/레코드 |
| 속성 | Attribute | - 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보 |
| 도메인 | Domain | - 각 속성들이 가질 수 있는 값의 집합 - 예) 성별 -> {남, 여} |
| 키 | Key | - 슈퍼키(유일성) -> 후보키(최소성) -> 기본키, 대체키 - 최소성 : 필드를 조합하지 않고 최소 필드만 써서 키 형성 가능 |
| 슈퍼키 | Super key | - 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키 |
| 후보키 | Candidate key | - 기본키가 될 수 있는후보, 유일성과 최소성 만족 |
| 기본키 | Primary Key | - 유일성과 최소성 만족 - 자연키 : 중복되지 않는 것을 자연스레 뽑은 키로 언젠가는 변함 - 인조키 : 인위적으로 생성한 키로 변하지 않음 |
| 대체키 | Alternate key | - 후보키가 2개 이상일 경우 어느 하나를 기본키로 지정하고 남은 후보키 |
| 외래키 | Foreign key | - 다른 테이블의 기본키를 그대로 참조하는 값 - 개체와의 관계 식별에 사용 |
| ERD | Entity Relationship Diagram | - 데이터베이스 구축 시 릴레이션 간의 관계 정의한 것 |
| 데이터베이스 이상현상 | Anomaly | - 필요한 데이터가 같이 삭제되거나 삽입하기 어려운 등의 현상 |
| 정규화 | Normalization | - 릴레이션 간의 잘못된 종속 관계로 인해 데이터베이스 이상 현상이 일어나서 이를 해결하는 과정 - 저장 공간을 효율적으로 사용하기 위해 릴레이션을 여러 개로 분리하는 과정 |
| 정규형 원칙 | - 자료의 중복성 감소, 독립적 관계는 별개의 릴레이션으로 표현, 각각의 릴레이션은 독립적 표현 | |
| 제1정규형 | 1NF | - 모든 도메인이 더 이상 분해될 수 없는 원자값만으로 구성되어 있다 - 예) 수정의 수강명 {python기본, 백엔드기초} -> 2개 레코드로 나눔 |
| 제2정규형 | 2NF | - 제1정규형 + 부분 함수의 종속성 제거한다 - 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속적이다 |
| 제3정규형 | 3NF | - 제2정규형 + 기본키가 아닌 모든 속성이 이행적 함수 종속을 만족하지 않는 상태이다 - A>B>C 라면 C가 A에 이행적으로 함수 종속(transitive FD)이 되었다 |
| 보이스/코드 정규형 | BCNF | - 제3정규형 + 결정자가 후보키가 아닌 함수 종속 관계 제거한다 - 릴레이션의 함수 종속 관계에서 모든 결정자가 후보키인 상태 |
| 데이터 타입 | Type | - TINYINT(1), SMALLINT(2), MEDIUMINT(3), INT(4), BIGINT(8) - DATE(3), DATETIME(8), TIMESTAMP(4) - CHAR, VARCHAR - TEXT : 큰 문자열 저장 / 주로 게시판 본문 저장 - BLOB : 이미지, 동영상 등 큰 데이터 저장 / 하지만 보통 S3에 저장 후 파일 경로를 VARCHAR 로 저장 - ENUM : 단일 선택 가능 - SET : 여러 개 선택 가능 |
| 트랜잭션 | Transaction | - 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업 단위 - 여러 개의 쿼리들을 하나로 묶는 단위 - ACID 특징이 있음 (원자성, 일관성, 독립성, 지속성) |
| 원자성 | Atomicity | - 트랜잭션과 관련된 일이 모두 수행되었거나 되지 않았거나를 보장하는 것 (all or nothing) |
| 커밋 | Commit | - 여러 쿼리가 성공적으로 처리되었다고 확정하는 명령어 - 트랜잭션 단위로 수행되고 변경 내용이 모두 영구적으로 저장됨 |
| 롤백 | Rollback | - 트랜잭션으로 처리한 하나의 묶음 과정을 일어나기 전으로 취소하는 명령어 - 커밋과 롤백으로 데이터 무결성 보장 |
| 트랜잭션 전파 | - 여러 트랜잭션 관련 메서드의 호출을 하나의 트랜잭션에 묶이도록 하는 것 -REQUIRED : 스프링이 제공하는 DEFAULT 전파 속성으로 2개의 논리 트랜잭션 묶어서 1개의 물리 트랜잭션 사용 - REQUIRED_NEW : 서로 다른 물리 트랜잭션을 별도로 가지고 각각 DB 커넥션이 사용됨 |
|
| 일관성 | Consistency | - 허용된 방식으로만 데이터를 변경해야 하는 것 |
| 격리성 | Isolation | - 트랜잭션 수행 시 서로 끼어들지 못하는 것 - 여러 개의 격리 수준으로 나누어 격리성 보장 |
| 격리 수준 | - (격리성) SERIALIZABLE > REPEATABLE_READ > READ_COMMITED > READ_UNCOMMITED (동시성) - 격리 수준에 따라 팬텀 리드, 더티 리드 등의 현상 발생 |
|
| 팬텀 리드 | Phantom read | - 한 트랜잭션 내에서 동일한 쿼리를 보냈을 때 해당 조회 결과가 다른(다른 행이 선택되는) 경우 - SERIALIZABLE 제외하고 발생 가능 |
| 반복 가능하지 않은 조회 | Non-repeatable read | - 한 트랜잭션 내의 같은 행에 두 번 이상 조회가 발생했는데 그 값이 다른 경우 - SERIALIZABLE, REPEATABLE_READ 제외하고 발생 가능 |
| 더티 리드 | Dirty read | - 반복 가능하지 않은 조회와 유사 - 한 트랜잭션이 실행 중일 때 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 행의 데이터 읽을 때 |
| SERIALIZABLE | - 트랜잭션을 순차적으로 진행시키는 것 - 여러 트랜잭션이 동시에 같은 행에 접근 불가, 성능 저하, 교착 상태 확률 높음 |
|
| REPEATABLE_READ | - 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막지만 새 행 추가는 막지 않음 | |
| READ_COMMITED | - 가장 많이 사용되는 격리 수준 - 커밋 완료된 데이터에 대해서만 조회 허용 - 특정 트랜잭션이 접근한 행을 다른 트랜잭션이 수정 가능 |
|
| READ_UNCOMMITED | - 가장 낮은 격리 수준, 성능 최고, 어림잡아 집계 시에만 사용 - 하나의 트랜잭션이 커밋되지 전에 다른 트랜잭션에 노출되기에 무결성을 위해 지양 |
|
| 지속성 | Durability | - 성공적으로 수행된 트랜잭션은 영원히 반영되어야 하는 것 - 데이터베이스에 시스템 장애가 발생해도 원 상태로 복구하는 회복 기능이 있어야 함 - 이를 위해 데이터베이스는 체크섬, 저널링, 롤백 등의 기능 제공 |
| 체크섬 | Checksum | - 중복 검사의 한 형태로, 오류 정정을 통해 송신된 자료의 무결성 보호하는 단순한 방법 |
| 저널링 | Journaling | - 파일 시스템 또는 DB 시스템에 변경사항을 커밋하기 전에 로깅하는 것 - 트랜잭션 등 변경 사항에 대한 로그를 남기는 것 |
| 무결성 | Integrity | - 데이터의 정확성, 일관성, 유효성을 유지하는 것 - 데이터 값과 현실 세계의 실제 값이 일치하는지에 대한 신뢰 확보 - 종류 : 개체 무결성, 참조 무결성, 고유 무결성, NULL 무결성 |
| 개체 무결성 | Entity integrity | - 기본키로 선택된 필드는 빈 값을 허용하지 않음 |
| 참조 무결성 | Referential integrity | - 서로 참조 관계에 있는 두 테이블의 데이터는 항상 일관된 값을 유지해야 함 |
| 고유 무결성 | Unique integrity | - 특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우 그 속성 값은 모두 고유해야 함 |
| NULL 무결성 | Null integrity | - 특정 속성 값에 NULL이 올 수 없다는 조건이 주어진 경우 그 속성 값은 NULL이 없어야 함 |
| 관계형 데이터베이스 | DBMS | - 행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스 |
| MySQL | - MyISAM 인덱스 압축 기술, B-트리 기반 인덱스, 스레드 기반 메모리 할당 시스템, 빠른 조인, 최대 64개 인덱스 제공, 롤백, 커밋, 이중 암호 지원 등 기능 제공 - 모듈식 아키텍처로 쉽게 스토리지 엔진 변경 가능 - 데이터 웨어하우징, 트랜잭션 처리, 고가용성 처리에 강점 |
|
| PostgreSQL | - VACUUM : 디스크 조각이 차지하는 영역을 회수할 수 있는 장치 - 최대 테이블 크기 32TB, JSON을 이용해 데이터 접근 가능 - 지정 시간에 복구하는 기능, 로깅, 접근 제어, 중첩 트랜잭션, 백업 등 가능 |
|
| MongoDB | - Binary JSON 형태로 데이터 저장, 키-값 데이터 모델에서 확장된 도큐먼트 기반의 데이터베이스 - 고가용성과 샤딩, 레플리카셋 지원 - 스키마를 정해 놓지 않고 데이터 삽입 가능해서 다양한 도메인의 DB 기반 분석/로깅에 강점 - 도큐먼트 생성 시마다 다른 컬렉션에서 중복된 값을 가지기 힘든 ObjectID 생성 (기본키) |
|
| redis | - 인메모리, 키-값 데이터 모델 기반의 데이터베이스 - 기본적인 데이터 타입 문자열(최대 512MB), 셋과 해시 등 지원 - pub/sub 기능을 통해 채팅 시스템, 다른 데이터베이스 앞단에 두고 사용하는 캐싱 계층, 세션 정보 관리, 정렬된 셋 자료 구조 이용한 실시간 순위표 서비스 등에 사용 |
|
| B-트리 | B-tree | - 일반적인 인덱스 저장 자료 구조 - 루프 노드를 거쳐 찾고자 하는 값이 있는 리프 노드의 데이터 포인터를 통해 반환 |
| 인덱스가 효율적인 이유 | - 균형 잡힌 트리 구조 - 트리 깊이의 대수확장성 : 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것으로 인덱스가 한 깊이 증가할 때마다 인덱스 항목의 수는 최대 4배 증가 |
|
| 인덱스 최적화 기법 | - 인덱스는 비용이다 - 인덱스 생성 후 반드시 테스팅하라 - 복합 인덱스는 같음(==), 정렬, 다중값(>/<), 카디널리티(유니크한 값 정도) 순으로 생성해야 한다 |
|
| 조인 | Join | - 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서 하나의 결과물을 만드는 것 - MySQL(JOIN), MongoDB(lookup-성능 안 좋음) |
| 내부 조인 | Inner join | - 일치하는 행이 있는 부분만 결과로 표기 |
| 왼쪽 조인 | Left outer join | - 왼쪽 테이블의 모든 행이 결과로 표기 |
| 오른쪽 조인 | Right outer join | - 오른쪽 테이블의 모든 행이 결과로 표기 |
| 합집합 조인 | Full outer join | - 두 개의 테이블을 기반으로 조인 조건에 만족하지 않는 행까지 모두 표기 |
| 중첩 루프 조인 | NLJ, Nested Loop join | - 중첩 for문과 같은 원리로 조인, 랜덤 접근에 대한 비용 증가로 대용량 테이블에서 미사용 - 조인 테이블을 블록으로 나눈 블록 중첩 루프 조인(BNL, Block Nested Loop) |
| 정렬 병합 조인 | Sort Merge Join | - 각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후에 조인 작업 수행 - 사용 : 조인할 때 쓸 적절한 인덱스 없음 + 대용량 테이블 + 조인 조건으로 <,> 연산자 사용 |
| 해시 조인 | Hash Join | - 해시 테이블 기반으로 조인 (MySQL8.0.18 릴리즈~) - 사용 : 하나의 테이블이 메모리에 완전 들어갈 수 있음 + 조인 조건으로 동등 연산자 - 단계 : 빌드 단계, 프로브 단계 - 사용 가능한 메모리양은 join_buffer_size에 의해 제어됨 |
| 빌드 단계 | Build-phase | - 입력 테이블(A,B) 중 작은 테이블(A) 하나를 기반으로 메모리 내 해시 테이블을 빌드하는 단계 - 조인에 사용되는 필드(A.col)가 해시 테이블의 키로 사용 |
| 프로브 단계 | Probe-phase | - 레코드 읽기 시작, hash(B.col)에 일치하는 레코드 찾아서 결과값 반환 |
REFERENCES
- [서적] 면접을 위한 CS 전공지식노트 (길벗, 2022)
- [블로그] Transaction 전파가 뭡니까?
