[CS] 기초 : 운영체제
운영체제 용어 :
컴퓨터 요소, 메모리 관리, 페이지 교체, 프로세스, PCB, IPC, CPU 스케줄링
1. 개념 구조화
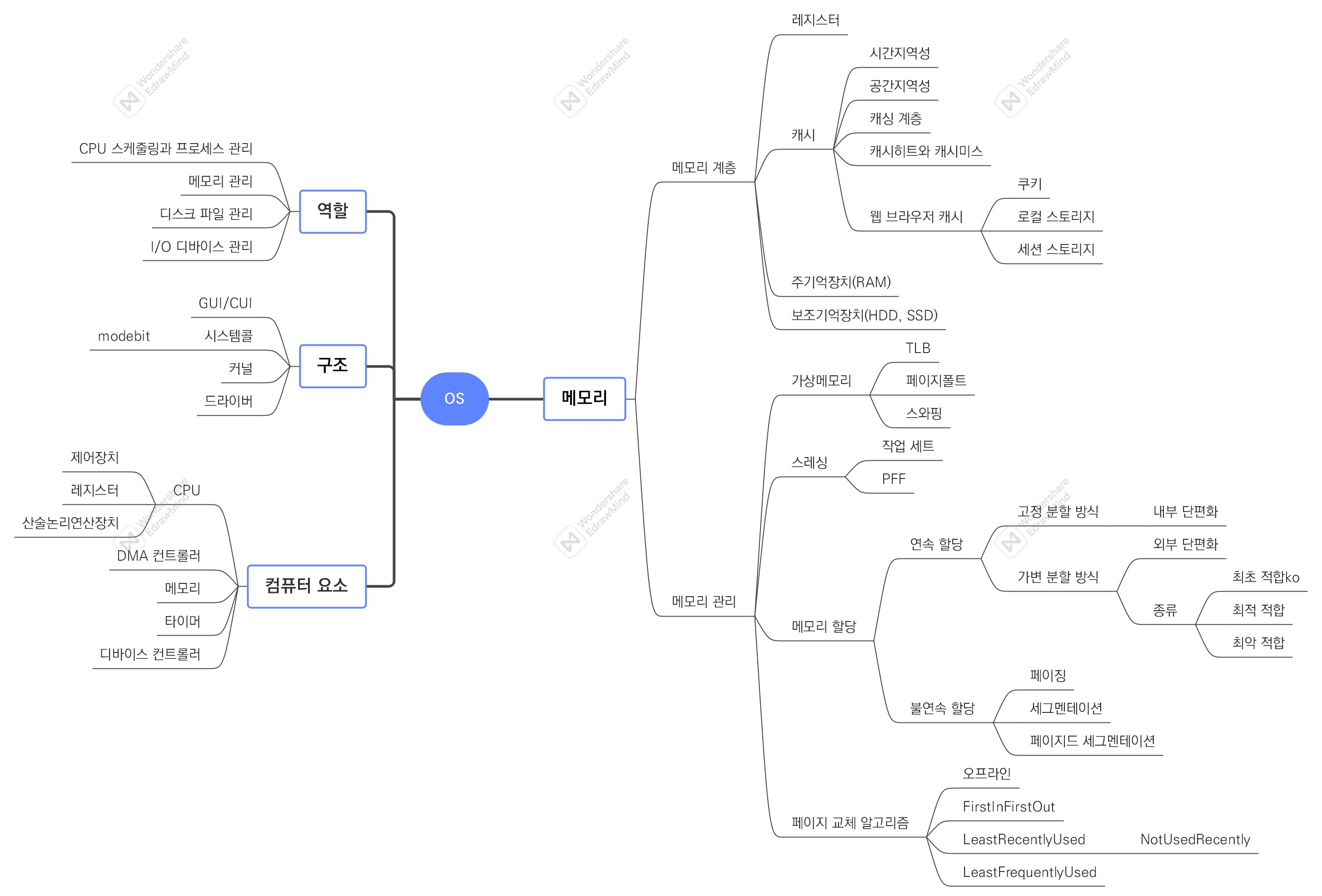
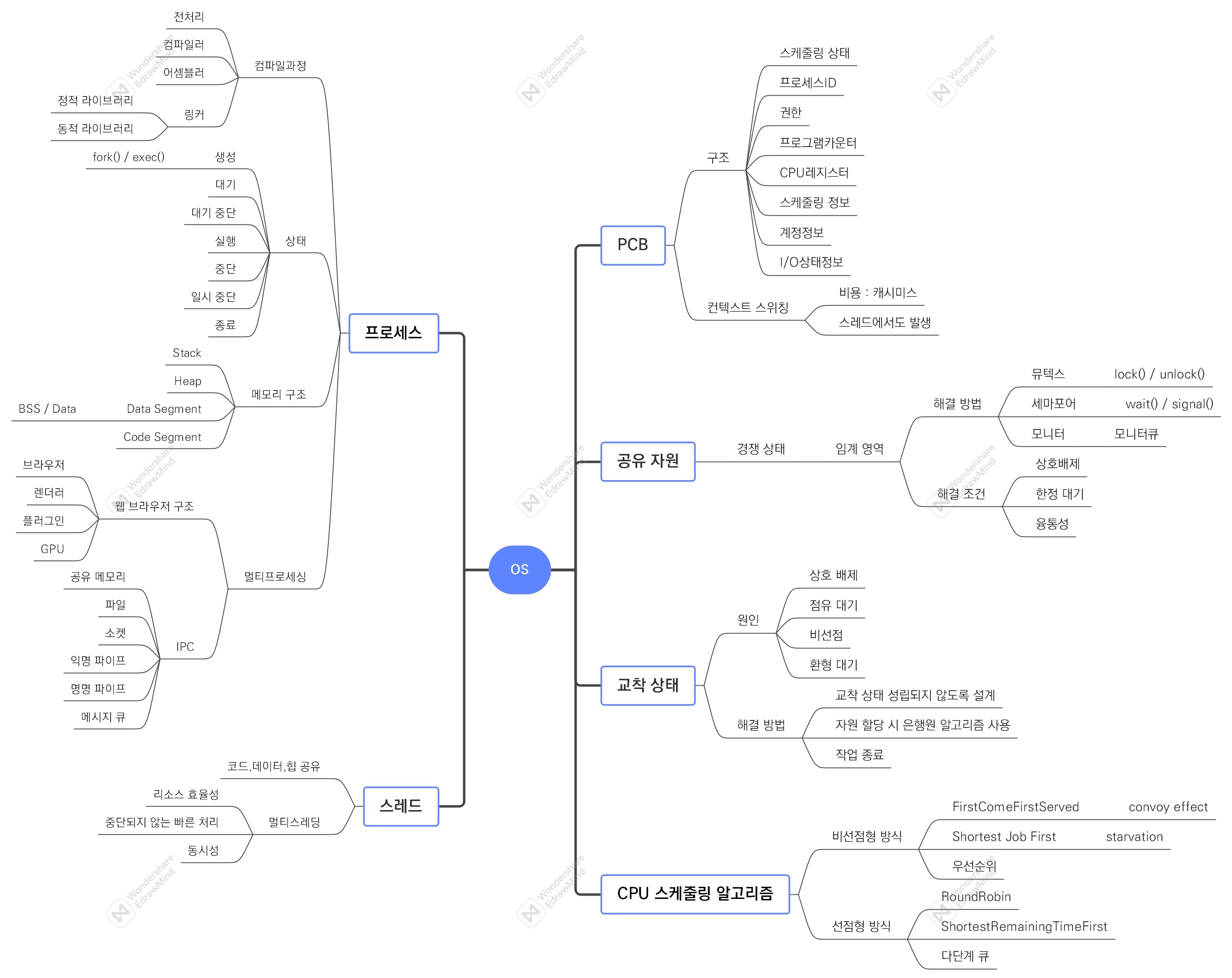
2. 개념 사전
| KOR | ENG | Meaning |
|---|---|---|
| 운영 체제 | Operating System | - 사용자가 컴퓨터를 쉽게 다루게 해주는 인터페이스 - 컴퓨터 자원을 통제하고 할당하는 공통 기능을 컴퓨터 소프트웨어 하나로 통합한 것 |
| 운영체제의 역할 | - CPU 스케줄링과 프로세스 관리 - 메모리 관리 - 디스크 파일 관리 - I/O 디바이스 관리 |
|
| 운영체제의 구조 | - 유저 프로그램과 하드웨어 사이에 있음 - GUI/CUI + 시스템콜 + 커널 + 드라이버 |
|
| 드라이버 | Driver | - 하드웨어를 제어하기 위한 소프트웨어 |
| 시스템콜 | Syscall | - 운영체제가 커널에 접근하기 위한 인터페이스 - 유저 프로그램이 운영체제의 서비스를 받기 위해 커널 함수 호출 시 사용 - 특히, 카메라, 키보드 등 I/O 디바이스는 운영체제를 통해서만 작동해야 함 - 유저 프로그램의 I/O 요청 -> 트랩 발동 -> 올바른 I/O 요청인지 확인 -> [시스템콜] 유저모드가 커널모드로 변환 -> 실행 - 컴퓨터 자원에 대한 직접 접근 차단 |
| I/O 요청 | I/O request | - 입출력 함수, 데이터베이스, 네트워크, 파일 접근 등에 관한 일 |
| modebit | modebit | - 시스템콜이 작동될 때 참고하는 플래그 변수로 유저 모드(1)와 커널 모드(0) 구분 - 시스템콜 호출 -> modebit = 0 -> 자원 이용한 로직 수행 -> modebit = 1 -> 이후 로직 수행 |
| 유저 모드 | User mode | - 유저가 접근할 수 있는 영역을 제한적으로 두며 컴퓨터 자원에 함부로 침범하지 못하는 모드 |
| 커널 모드 | Kernel mode | - 모든 컴퓨터 자원에 접근할 수 있는 모드 |
| 커널 | Kernel | - 운영체제의 핵심 - 메모리에 상주하면서 운영체제의 다른 부분/응용 프로그램 수행에 필요한 환경 설정하는 SW - 시스템콜 인터페이스 제공, 보안, 메모리, 프로세스, 파일 시스템, I/O 디바이스, I/O 요청 관리 등 역할 |
| 컴퓨터 요소 | - CPU, DMA 컨트롤러, 메모리, 타이머, 디바이스 컨트롤러 등 | |
| CPU | Central Processing Unit | - 산술논리연산장치 + 제어장치 + 레지스터로 구성된 컴퓨터 장치 - 인터럽트에 의해 단순히 메모리에 존재하는 명령어 해석 및 실행 |
| 제어장치 | Control Unit | - 프로세스 조작을 지시하는 CPU의 한 부품 - 입출력장치 간 통신 제어, 명령어 읽고 해석, 데이터 처리를 위한 순서 결정 |
| 레지스터 | Register | - CPU 안에 있는 매우 빠른 임시기억장치 - 연산 속도가 메모리보다 수십 배~수백 배 빠름 - 레지스터를 거쳐 데이터 전달 |
| 산술논리연산장치 | Arithmetic Logic Unit | - 두 숫자의 산술 연산, 배타적 논리합, 논리곱 같은 논리 연산 계산하는 디지털 회로 |
| 인터럽트 | Interrupt | - 어떤 신호가 들어왔을 때 CPU를 잠깐 정지시키는 것 (IO 디바이스, 0으로 나눔, 프로세스 오류 등) - 인터럽트 발생 -> 인터럽트 벡터로 감 -> 인터럽트 핸들러 함수 실행 - 인터럽트 간에 우선순위 존재 - 하드웨어 인터럽트, 소프트웨어 인터럽트 |
| 하드웨어 인터럽트 | - 마우스 연결 등 IO 디바이스에서 발생하는 인터럽트 - 디바이스에 있는 로컬 버퍼에 접근하여 일 수행 |
|
| 소프트웨어 인터럽트 | Trap | - 프로세스 오류 등으로 프로세스가 시스템콜 호출 시 발생하는 인터럽트 |
| DMA 컨트롤러 | DMA Controller | - I/O 디바이스가 메모리에 직접 접근할 수 있도록 하는 하드웨어 장치 - CPU 부하 방지를 위해 CPU 일 부담하는 보조 일꾼 - CPU와 DMA 컨트롤러가 하나의 작업을 동시에 하는 것 방지 |
| 메모리 | Memory (RAM) | - 전자회로에서 데이터나 상태, 명령어 등 기록하는 장치 - CPU는 계산 담당(일꾼), RAM은 기억 담당(작업장) |
| 타이머 | Timer | - 몇 초 안에는 작업이 끝나야 한다는 것을 정하고 특정 프로그램에 시간 제한을 다는 역할 |
| 디바이스 컨트롤러 | Device Controller | - 컴퓨터와 연결되어 있는 IO 디바이스들의 작은 CPU - 디바이스 컨트롤러 옆에 붙어있는 로컬 버퍼는 각 디바이스에서 데이터를 임시로 저장 위한 작은 메모리 |
| 메모리 계층 | - 레지스터, 캐시, 주기억장치, 보조기억장치 | |
| 캐싱 계층 | - 속도 차이를 해결하기 위해 계층과 계층 사이에 있는 계층 - 레디스도 데이터베이스 계층의 캐싱 계층으로 사용 |
|
| 지역성 | Locality | - 자주 사용하는 데이터에 대한 근거 |
| 시간 지역성 | Temporal locality | - 최근 사용한 데이터에 다시 접근하려는 특성 |
| 공간 지역성 | Spatial locality | - 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성 |
| 캐시히트 | Cache hit | - 캐시에서 원하는 데이터를 찾는 것 |
| 캐시미스 | Cache miss | - 원하는 데이터가 캐시에 없으면 주메모리로 가서 데이터 찾아오는 것 |
| 캐시매핑 | Cache mapping | - 캐시가 히트되기 위해 매핑하는 방법 - 직접 매핑, 연관 매핑, 집합 연관 매핑 |
| 웹 브라우저 캐시 | - 쿠키 : 만료기한 있는 키-값 저장소, httponly 옵션, 4KB - 로컬 스토리지 : 만료기한 없는 키-값 저장소, 도메인 단위, 10MB, 클라이언트만 - 세션 스토리지 : 만료기한 없는 키-값 저장소, 탭 단위, 탭 닫으면 삭제, 5MB, 클라이언트만 |
|
| 메모리 관리 | ||
| 가상 메모리 | Virtual memory | - 메모리 기법 관리 중 하나 - 컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 사용자에게 매우 큰 메모리로 보이도록 하는 것 - 가상 주소 -> (MMU, 메모리관리장치) -> 실제 주소 - 가상 주소와 실제 주소가 매핑되어 있고, 프로세스의 주소 정보가 들어있는 페이지 테이블로 관리됨 - 속도 향상을 위해 TLB를 활용 |
| 페이지 테이블 | Page table | - 하드디스크에 옮겨놓은 페이지들을 사용할 때 참조하는 테이블로 OS가 관리 - 프로세스별로 논리주소와 메모리의 물리주소 간 매핑 테이블 - valid bit으로 물리적 메모리(DRAM)에 올라가 있는지 아닌지 나타냄 |
| TLB | Translation Lookaside Buffer | - 메모리와 CPU 사이에 있는 주소 변환을 위해 페이지 테이블의 캐시 데이터 - CPU 코어의 MMU에 보관해서 CPU가 페이지 테이블까지 가지 않도록 하는 캐시 계층 |
| 페이지 폴트 | Page fault | - 프로세스 주소 공간에는 존재하지만 RAM에는 없는 데이터에 접근할 경우 발생 - valid bit가 0인 페이지에 CPU가 접근 시 페이지 폴트 발생 |
| 스와핑 | Swapping | - 메모리에서 당장 사용하지 않는 영역을 하드디스크로 옮기고(스왑 아웃) 하드디스크의 일부분을 메모리로 불러와 쓰는 것(스왑 인) - 페이지 폴트가 발생할 때 마치 일어나지 않은 것처럼 만듦 - CPU 가 물리 메모리 확인 -> 페이지 폴트 발생 -> MMU가 트랩 발생 -> OS가 CPU 동작 중지 -> OS가 페이지 테이블에서 가상 메모리에 페이지 존재하는지 확인 -> 없으면 프로세스 중단 -> 현재 물리 메모리에 빈 프레임 없으면 스와핑 발동(스왑아웃) -> 빈 프레임에 해당 페이지 로드(스왑인) -> 페이지 테이블 최신화 -> 중단된 CPU 다시 시작 |
| 페이지 | Page | - 가상 메모리 사용하는 최소 크기 단위 |
| 프레임 | Frame | - 실제 메모리 사용하는 최소 크기 단위 |
| 스레싱 | Thrashing | - 메모리의 페이지 폴트율이 높은 것으로 컴퓨터의 심각한 성능 저하 초래 - 페이지 폴트 및 스와핑 발생 -> CPU 이용률 낮아짐 -> 가용성 높이기 위해 OS가 프로세스를 더 많이 메모리에 올림 -> 악순환 반복 -> 스레싱 발생 - 해결 방법 : 메모리 늘림, HDD를 SDD로 변경, 작업 세트, PFF |
| 작업 세트 | Working set | - 프로세스의 과거 사용 이력인 지역성을 통해 결정된 페이지 집합을 만들어 미리 메모리에 로드 |
| PFF | Page Fault Frequency | - 페이지 폴트 빈도의 상한선과 하한선 만들어 조절 - 상한선 도달 시 프레임 늘리고, 하한선 도달 시 프레임 줄이기 |
| 메모리 할당 | - 메모리에 프로그램 할당 시, 시작 메모리 위치와 메모리 할당 크기 기반으로 할당 | |
| 연속 할당 | Contiguous allocation | - 메모리에 연속적으로 공간 할당 - 고정 분할 방식, 가변 분할 방식 |
| 고정 분할 방식 | Fixed partition allocation | - 메모리를 미리 나누어 관리하는 방식으로 내부 단편화 발생 |
| 내부 단편화 | Internal fragmentation | - 메모리를 나눈 크기보다 프로그램이 작아서 남은 공간을 다른 작업이 사용 못하는 현상 |
| 가변 분할 방식 | Variable partition allocation | - 매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용하며 외부 단편화 발생 - 종류 : 최초적합, 최적적합, 최악적합 |
| 외부 단편화 | External fragmentation | - 메모리를 나눈 크기보다 프로그램이 커서 들어가지 못하는 공간이 많이 발생하는 현상 |
| 최초 적합 | First fit | - 위/아래쪽부터 시작해서 홀(할당 가능한 빈 메모리 공간)을 찾으면 바로 할당 |
| 최적 적합 | Best fit | - 프로세스의 크기 이상인 공간 중 가장 작은 홀부터 할당 |
| 최악 적합 | Worst fit | - 프로세스의 크기와 가장 많이 차이가 나는 홀에 할당 |
| 불연속 할당 | Noncontiguous allocation | - 현대 운영체제가 쓰는 방법 - 기법 : 페이징, 세그멘테이션, 페이지드 세그멘테이션 등 있음 |
| 페이징 | Paging | - 프로그램과 메모리를 동일한 크기의 페이지로 나누고 메모리의 서로 다른 위치에 프로세스 할당 - 프로그램마다 페이지 테이블을 두어 메모리에 프로그램 할당 - 장점 : 홀 크기가 균일함 - 단점 : 주소 변환이 복잡해짐 |
| 세그멘테이션 | Segmentation | - 프로그램을 의미 단위인 세그먼트로 나누는 방식 - 프로세스를 이루는 메모리 = 코드 영역 + 데이터 영역 + 스택 영역 + 힙 영역 - 코드와 데이터로 나누거나 코드 내의 작은 함수를 세그먼트로 놓고 나눔 - 장점 : 공유와 보안 측면에서 좋음 - 단점 : 홀 크기가 균일하지 않음 |
| 페이지드 세그멘테이션 | Paged segmentation | - 프로그램을 의미 단위인 세그먼트로 나누고, 동일한 크기의 페이지 단위로 나누는 방식 |
| 페이지 교체 알고리즘 | - 스와핑이 많이 일어나지 않도록 하기 위해 사용하는 알고리즘 - 종류 : 오프라인, FIFO, LRU, NUR, LFU 등 |
|
| 오프라인 알고리즘 | Offline algorithm | - 먼 미래에 참조되는 페이지와 현재 할당하는 페이지 바꾸는 알고리즘 - 가장 이상적, 성능 비교에 대한 상한 기준 제공 |
| FIFO | First In First Out | - 가장 먼저 온 페이지를 교체 영역에 가장 먼저 놓는 방법 |
| LRU | Least Recently Used | - 참조가 가장 오래된 페이지 교체 - 오래된 것을 파악하기 위해 각 페이지마다 계수기, 스택을 두어야 함 |
| NUR | Not Used Recently | - LRU에서 발전한 알고리즘으로 clock 알고리즘 - 0과 1을 가진 비트를 두고 시계방향으로 돌면서 0을 찾은 순간 해당 프로세스를 교체하고 1로 바꿈 |
| LFU | Least Frequently Used | - 가장 참조 횟수가 적은 페이지 교체 |
| 프로세스와 스레드 | ||
| 프로세스 | Process | - 프로그램이 메모리에 올라가 인스턴스화된 것으로 CPU 스케줄링 대상인 task와 같은 의미 |
| 컴파일 과정 | - 전처리 > 컴파일러 > 어셈블러 > 링커 - 전처리 : 소스 코드의 주석을 제거하고 #include 등 헤더 파일 병합 -> 매크로 치환 - 컴파일러 : 오류 처리, 코드 최적화 작업 -> 어셈블리어로 변환 - 어셈블러 : 어셈블리어는 목적 코드로 변환 -> ‘파일명.o’ 파일 생성 - 링커 : 라이브러리 함수/다른 파일들과 목적 코드 결합 -> ‘파일명.exe/파일명.out’ 실행 파일 생성 |
|
| 정적 라이브러리 | - 프로그램 빌드 시 라이브러리가 제공하는 모든 코드를 실행 파일에 넣어서 사용하는 방법 - 시스템 환경 등 외부 의존도가 낮지만 코드 중복 등의 메모리 효율성 떨어짐 |
|
| 동적 라이브러리 | - 프로그램 실행 시 필요할 때만 DLL(동적 링크 라이브러리) 함수 정보를 통해 참조해 사용하는 방법 - 메모리 효율성에서 좋지만 외부 의존도가 높아짐 |
|
| 프로세스 상태 | - 생성, 대기, 대기 중단, 실행, 중단, 일시 중단, 종료 | |
| 생성 상태 | Create | - 프로세스가 생성된 상태로 fork(), exec() 함수를 통해 생성되고 PCB 할당 |
| fork() | - 부모 프로세스의 주소 공간을 그대로 복사하며 새로운 자식 프로세스 생성하는 함수 - 부모 프로세스의 비동기 작업 등을 상속하지 않음 |
|
| exec() | - 새롭게 프로세스 생성하는 함수 | |
| 대기 상태 | Ready | - 메모리 공간이 충분하면 메모리를 할당받고 아니면 아닌 상태로 대기하고 있으며 CPU 스케줄러부터 CPU 소유권이 넘어오기를 기다리는 상태 |
| 대기 중단 상태 | Ready suspended | - 메모리 부족으로 일시 중단된 상태 |
| 실행 상태 | Running | - CPU 소유권과 메모리를 할당받고 인스트럭션을 수행 중인 상태 (CPU burst) |
| 중단 상태 | Blocked | - 어떤 이벤트가 발생한 이후 기다리며 프로세스가 차단된 상태 |
| 일시 중단 상태 | Blocked suspended | - 중단된 상태에서 프로세스가 실행되려고 했지만 메모리 부족으로 일시 중단된 상태 |
| 종료 상태 | Terminated | - 메모리와 CPU 소유권을 모두 놓고 가는 상태 - 부모 프로세스가 자식 프로세스를 강제시키는 비자발적 종료(abort)도 있음 |
| 프로세스 메모리 구조 | - 스택, 힙, 데이터 영역, 코드 영역 구조 기반으로 할당 - 동적 할당(스택, 힙) : 런타임 단계에서 메모리 할당받는 것 - 정적 할당(데이터 영역, 코드 영역) : 컴파일 단계에서 메모리 할당하는 것 |
|
| 스택 | Stack | - 지역 변수, 매개변수, 실행되는 함수에 의해 늘어들거나 줄어드는 메모리 영역 - 함수가 호출될 때마다 호출될 때의 환경 등 정보가 저장됨 - 재귀 함수 호출 시 새로운 스택 프레임이 매번 사용되어 함수 내의 변수 집합이 다른 인스턴스 변수 방해하지 않음 |
| 힙 | Heap | - 동적으로 할당되는 변수 담음 - malloc(), free() 함수를 통해 관리 가능 - 동적으로 관리되는 자료 구조(ex.vector)의 경우 힙 영역 사용 |
| 데이터 영역 | BSS segment, Data Segment | - BSS segment : 전역변수/static/const로 선언되어 있고 0으로 초기화/초기화 값이 없는 변수가 해당 영역에 할당 - Data segment : 전역변수/static/const로 선언되어 있고 0이 아닌 값으로 초기화된 변수가 해당 영역에 할당 |
| 코드 영역 | Code segment | - 프로그램의 코드 |
| PCB | Process Control Block | - 운영체제에서 프로세스에 대한 메타데이터를 저장한 데이터로 프로세스 생성되면 생성 - 프로세스의 메타데이터들을 담고 있기에 일반 사용자 접근 못하도록 커널 스택의 가장 앞부분에서 관리됨 |
| PCB 구조 | - 프로세스 스케줄링 상태 : 프로세스가 CPU에 대한 소유권을 얻은 이후의 상태 - 프로세스 ID : 프로세스 ID, 해당 프로세스의 자식 프로세스 ID - 프로세스 권한 : 컴퓨터 자원 또는 I/O 디바이스에 대한 권한 정보 - 프로그램 카운터 : 프로세스에서 실행해야 할 다음 명령어의 주소에 대한 포인터 - CPU 레지스터 : 프로세스를 실행하기 위해 저장해야 할 레지스터에 대한 정보 - CPU 스케줄링 정보 : CPU 스케줄러에 의해 중단된 시간 등에 대한 정보 - 계정 정보 : 프로세스 실행에 사용된 CPU 사용량, 실행한 유저의 정보 - I/O 상태 정보 : 프로세스에 할당된 I/O 디바이스 목록 |
|
| 컨텍스트 스위칭 | Context switching | - PCB를 교환하는 과정으로 한 프로세스에 할당된 시간이 끝나거나 인터럽트에 의해 발생 - 컨텍스트 스위칭이 빠르게 일어나서 많은 프로세스가 동시에 구동되는 것처럼 보임 - 인터럽트 발생 -> 프로세스 A의 PCB 저장 -> 프로세스 B의 PCB 로드 -> … - 유휴 시간과 캐시미스라는 비용 발생 - 스레드는 스택 영역 제외한 모든 메모리 공유하기 때문에 스레드 컨텍스트 스위칭의 경우 비용이 더 적고 시간도 적게 듦 |
| 캐시미스 | - 컨텍스트 스위칭이 일어날 때 프로세스가 가지고 있는 메모리 주소가 그대로 있으면 잘못된 주소 변환이 생기므로 캐시클리어 과정을 겪는데 이로 인해 캐시미스 발생 | |
| 멀티프로세싱 | - 하나 이상의 일을 병렬로 처리 가능 - 특정 프로세스의 메모리, 프로세스 중 일부에 문제 발생 시에도 다른 프로세스로 처리 가능 |
|
| 웹 브라우저의 멀티프로세스 구조 | - 브라우저 프로세스 : 주소 표시줄, 뒤로 가기 버튼 등 담당하며 네트워크 요청이나 파일 접근 권한 담당 - 렌더러 프로세스 : 웹 사이트가 보이는 부분의 모든 것 제어 - 플러그인 프로세스 : 웹 사이트에서 사용하는 플러그인 제어 - GPU 프로세스 : GPU를 이용해서 화면을 그리는 부분 제어 |
|
| IPC | Inter Process Communication | - 프로세스끼리 데이터를 주고받고 공유 데이터를 관리하는 매커니즘 - 종류 : 공유 메모리, 파일, 소켓, 익명 파이프, 명명 파이프, 메시지 큐 등 - 위 종류 모두 메모리 완전 공유되는 스레드보다는 속도 떨어짐 |
| 공유 메모리 | Shared memory | - 공유 메모리를 통해 여러 프로세스가 하나의 메모리 공유 및 통신 - 불필요한 데이터 복사의 오버헤드 발생하지 않고 IPC 방식 중 가장 빠름 - 여러 프로세스가 같은 메모리 공유하기에 동기화 필요 |
| 파일 | File | - 프로세스 간 통신 - 디스크에 저장된 데이터 또는 파일 서버에서 제공한 데이터 기반 |
| 소켓 | Socket | - 프로세스 간, 동일한 네트워크의 서버 간 통신 - 네트워크 인터페이스를 통해 전송하는 데이터 기반 - TCP / UDP |
| 익명 파이프 | Unnamed pipe | - 부모, 자식 프로세스 간 통신 (네트워크 다르면 불가능) - 프로세스 간에 FIFO 방식으로 읽히는 임시 공간인 파이프 기반으로 데이터 통신 - 단방향 방식의 읽기 전용, 쓰기 전용 파이프 생성 및 작동 |
| 명명 파이프 | Named pipe | - 프로세스 간, 다른 네트워크의 서버 간 통신 - 파이프 서버와 하나 이상의 파이프 클라이언트 간의 통신을 위해 명명된 단/양방향 파이프 - 클라이언트/서버 통신을 위한 별도 파이프 제공 (파이프 인스턴스) - 여러 파이프 동시에 사용 가능 |
| 메시지 큐 | Message queue | - 메시지를 큐 데이터 구조 형태로 관리하며 커널에서 전역적으로 관리됨 - 다른 IPC에 비해 사용 방법이 직관적이고 간단 - 공유 메모리를 통해 IPC 구현 시 동기화 때문에 기능 구현이 복잡할 경우 대안으로 사용 |
| 스레드 | Thread | - 프로세스의 실행 가능한 가장 작은 단위로 한 프로세스에 여러 스레드 있음 - 코드, 데이터, 힙은 스레드끼리 공유 (프로세스는 각각 생성) - 상태, 스택은 스레드 별로 각각 생성 |
| 멀티스레딩 | - 프로세스 내 작업을 여러 개의 스레드, 멀티스레드로 처리하는 기법 - 스레드끼리 서로 자원 공유하기 때문에 효율성이 높음 - 새 프로세스 생성 대신 스레드를 사용 -> 리소스 효율성, 중단되지 않은 빠른 처리, 동시성 - 한 스레드에 문제 -> 다른 스레드에도 영향 -> 스레드로 이뤄진 프로세스에 영향 |
|
| 동시성 | - 서로 독립적인 작업들을 작은 단위로 나누고 동시에 실행되는 것처럼 보여주는 것 | |
| 공유 자원 | Shared resource | - 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 모니터, 프린터, 메모리, 데이터 등 자원이나 변수 - 경쟁 상태 : 공유 자원을 두 개 이상의 프로세스가 동시에 읽거나 쓰는 상황으로 접근 타이밍이나 순서 등이 결과값에 영향을 줄 수 있음 |
| 임계 영역 | Critical section | - 둘 이상의 프로세스, 스레드가 공유 자원에 접근할 때 순서 등의 이유로 결과가 달라지는 코드 영역 - 해결 방법 : 뮤텍스, 세마포어, 모니터 - 위 3가지 해결 방법은 잠금(lock) 매커니즘 사용 -> 상호 배제, 한정 대기, 융통성 조건 만족 |
| 상호 배제 | - 한 프로세스가 임계 영역에 들어갔을 때 다른 프로세스는 들어갈 수 없음 | |
| 한정 대기 | - 특정 프로세스가 영원히 임계 영역에 들어가지 못하면 안 됨 | |
| 융통성 | - 한 프로세스가 다른 프로세스의 일을 방해해서는 안 됨 | |
| 뮤텍스 | Mutex | - 잠금 기반으로 상호배제가 일어나는 잠금 매커니즘 - 프로세스나 스레드가 공유 자원을 lock() -> unlock() - 잠금 설정되면 다른 프로세스나 스레드가 해당 코드 영역에 접근 불가 - 잠금 / 잠금 해제 상태만 가짐 |
| 세마포어 | Semaphore | - 신호 기반 상호배제가 일어나는 신호 매커니즘 - 일반화된 뮤텍스로 정수값과 wait(), signal() 함수로 접근 처리 - wait() : 자신의 차례가 올 때까지 기다리는 함수 - signal() : 다음 프로세스로 순서를 넘겨주는 함수 - 프로세스/스레드가 세마포어 값 수정 시 다른 프로세스가 동시에 세마포어 값 수정 불가 |
| 바이너리 세마포어 | - 0과 1의 두 가지 값만 가지는 세마포어 | |
| 카운팅 세마포어 | - 여러 개의 값을 가질 수 있는 세마포어, 여러 자원에 대한 접근 제어 시 사용 | |
| 모니터 | Monitor | - 둘 이상의 스레드나 프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유 자원 숨기고 인터페이스만 제공 - 모니터큐를 통해 공유 자원에 대한 작업들을 순차적으로 처리 - 세마포어와 달리 상호 배제가 자동으로 구현됨 |
| 교착 상태 | Deadlock | - 두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태 |
| 교착 상태의 원인 | - 상호 배제 : 한 프로세스가 자원을 독점하고 있으며 다른 프로세스는 접근 불가능 - 점유 대기 : 특정 프로세스가 점유한 자원을 다른 프로세스가 요청하는 상태 - 비선점 : 다른 프로세스의 자원을 강제적으로 선점 불가능 - 환형 대기 : A는 B의 자원을 요구하고 B는 A의 자원을 요구하는 등 서로 자원 요구하는 상황 |
|
| 교착 상태의 해결 방법 | - 자원 할당 시 애초에 교착 상태 조건이 성립되지 않도록 설계 - 교착 상태 가능성이 없을 때만 자원이 할당되고, 프로세스당 요청할 자원 최대치를 통해 할당 가능 여부 파악하는 은행원 알고리즘 사용 - 교착 상태 발생 시 사이클을 찾아보고 이와 관련된 프로세스 하나씩 지움 - 교착 상태 처리 비용이 더 커서 발생 시 사용자가 작업 종료 |
|
| 은행원 알고리즘 | Banker’s algorithm | - 총 자원 양과 현재 할당한 자원 양 기준으로 안정/불안정 상태로 나누고 안정 상태로 가도록 자원 할당하는 알고리즘 |
| CPU 스케줄링 알고리즘 | - CPU 스케줄러는 알고리즘에 따라 프로세스에서 해야 하는 일을 스레드 단위로 CPU에 할당 - 어떤 프로그램에 CPU 소유권을 줄 지 결정하는 알고리즘 - 목표 : CPU 이용률 높게, 주어진 시간에 많은 일을 하게, 준비 큐의 프로세스 적게, 응답시간 짧게 |
|
| 비선점형 방식 | Non-preemptive | - 프로세스가 스스로 CPU 소유권을 포기하는 방식 - 강제로 프로세스 중지하지 않기 때문에 컨텍스트 스위칭으로 인한 부하 적음 |
| FCFS | First Come, First Served | - 가장 먼저 온 것을 가장 먼저 처리 - 길게 수행되는 프로세스로 인해 준비큐에서 오래 기다리는 현상(convoy effect) 발생 |
| SJF | Shortest Job First | - 실행 시간이 가장 짧은 프로세스 가장 먼저 처리 - 과거 실행했던 시간을 토대로 추측해서 사용, 평균 대기시간 가장 짧음 - 긴 시간을 가진 프로세스가 실행되지 않는 현상(starvation) 발생 |
| 우선순위 | Priority | - SJF의 starvation을 보완하여 오래된 작업일수록 우선순위를 높이는 방법(aging)을 추가 |
| 선점형 방식 | Preemptive | - 현대 운영체제가 쓰는 방식 - 지금 사용하고 있는 프로세스를 강제 중단 후 다른 프로세스에 CPU 소유권 할당하는 방식 |
| RR | Round Robin | - 현대 컴퓨터가 쓰는 우선순위 스케줄링의 일종 - 각 프로세스는 동일한 할당 시간을 주고 시간 내에 끝나지 않으면 다시 준비큐의 뒤로 감 - 할당시간 큼 -> FCFS - 할당시간 작음 -> 컨텍스트 스위칭 많아짐 -> 오버헤드(비용) 커짐 - 전체 작업 길어짐, 평균 응답 시간 짧아짐 - 로드밸런서에서 트래픽 분산 알고리즘으로 사용 |
| SRF | Shortest Remaining Time First | - 작업 도중에 더 짧은 작업이 들어오면 수행하던 프로세스 중지하고 해당 프로세스 수행 |
| 다단계 큐 | Multilevel queue | - 우선순위에 따른 준비 큐 여러 개 사용 - 큐마다 라운드 로빈, FCFS 등 다른 스케줄링 알고리즘 적용 - 큐 간의 프로세스 이동이 안 되어서 스케줄링 부담 적지만 유연성 떨어짐 - 예) 높은 우선순위의 시스템 프로세스는 FCFS, 낮은 우선순위의 배치 프로세스는 RR |
REFERENCES
- [서적] 면접을 위한 CS 전공지식노트 (길벗, 2022)
- [블로그] 가상메모리와 페이지폴트
